 De basics om je eerste eigen cluster te maken
De basics om je eerste eigen cluster te maken
Wellicht dat je ooit als klein bedrijfje bent begonnen met een Apache webserver op een oude Fedora machine op je zolderkamer. Ben je inmiddels uitgegroeid tot een multinational, dan wordt het hoog tijd die stand-alone server te migreren naar een HA cluster. In dit artikel lees je hoe.
Het mag voor zich spreken waarom je een high availability (HA) cluster in zou willen richten: het zorgt ervoor dat belangrijke services altijd beschikbaar zijn. Nou ja, altijd.. Helemaal altijd kan niet. Dit komt door de manier waarop een HA cluster zijn werk doet. Het cluster houdt de servers in het cluster in de gaten. Daarnaast worden de services gemonitord die in het cluster draaien. Gaat een server of gemonitorde service down, dan zorgt het cluster ervoor dat deze zo snel mogelijk weer gestart wordt. Gezien deze manier van werken, is het dus onvermijdelijk dat een korte periode bestaat, waarop de services niet beschikbaar zijn.
Deze tijdelijke onbeschikbaarheid klinkt echter veel erger dan dat het daadwerkelijk is. Een goed ingericht cluster reageert snel. Dat betekent dat in veel gevallen binnen enkele tientallen seconden actie ondernemen wordt en de cluster service alweer opnieuw aan het starten is. Vervolgens ben je afhankelijk van de tijd die het kost om de service te starten. Doet jouw Oracle database er normaal ook al 3 minuten over? Dan zal het in het cluster niet heel veel sneller gaan. Voor een gemiddelde webserver zal die tijd aanmerkelijk korter zijn. Vaak gaat het zo snel dat de eindgebruiker weliswaar een korte hapering waarneemt, maar na nog een keer klikken gewoon weer verder kan werken. Een waardevolle toevoeging dus als je een webwinkel runt en je klanten zoveel mogelijk van dienst wilt zijn!
Ingrediënten van een cluster
Om een cluster in te richten, heb je een aantal ingrediënten nodig. Om te beginnen is dat de nodige hardware. Uiteraard zal je minstens 2 servers aan moeten schaffen. Dat mogen virtuele servers zijn, maar dan moet je er wel voor zorgen dat je virtualisatieplatform de beschikbaarheid van die virtuele servers garandeert. Daarnaast heb je een netwerk nodig. Bij voorkeur is dat naast het netwerk dat normaal gebruikt wordt voor communicatie met gebruikers ook nog een apart netwerk waarop het cluster verkeer plaatsvindt.
Een ander belangrijk basiscomponent van het cluster is gedeelde opslag. Je wilt immers dat je webserver (of wat voor service je ook gaat clusteren) na een migratie naar een andere cluster node gewoon nog bij dezelfde gegevens kan. Om dat te regelen, moet je de gegevens opslaan op een SAN. Tot slot wil je een voorziening hebben voor Fencing of STONITH. Dit zorgt ervoor dat een server waarvan waargenomen is dat deze niet langer beschikbaar is, getermineerd wordt. Dit is nodig om ervoor te zorgen dat niet onverhoopt twee servers dezelfde service aanbieden, wat zou kunnen leiden tot corruptie. In figuur 1 zie je schematisch alle basisingrediënten van het cluster weergegeven.
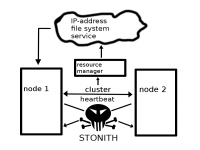
Schematisch overzicht van het cluster
Software benodigdheden
Als alle hardware op zijn plaats staat, kun je beginnen met het inrichten van de software laag. Het maakt overigens niet zo heel veel uit welke Linux distributie je gebruikt, de software is voor alle belangrijke distributies beschikbaar via de standaard repositories.
De cluster software bestaat uit twee lagen. Op de onderste laag houden de cluster nodes elkaar in de gaten. Deze laag wordt aangeduid als de ‘membership layer’. Op de laag daarboven worden de resources in de gaten gehouden. Deze laag wordt aangeduid als de ‘resource manager’. Uiteraard communiceren de lagen intensief met elkaar, zodat ervoor gezorgd kan worden dat het cluster actie onderneemt wanneer iets mis gaat en nodes of services niet langer beschikbaar zijn.
De meest gangbare software die momenteel gebruikt wordt voor de membership layer is corosync. Als je echter in een Red Hat omgeving werkt, kun je als alternatief ook nog de oudere Red Hat oplossing cman tegenkomen. In dit artikel richten we ons op de configuratie van corosync, want dit is ook op Red Hat de oplossing die de toekomst heeft. Cman zal langzaamaan steeds meer naar de achtergrond verdwijnen.
Op de resource management laag is Pacemaker momenteel de heersende oplossing. Dit is een verbetering van de oudere oplossing die Heartbeat heette. De ontwikkelaars vonden na een knallende interne ruzie die laag zó slecht, dat een Pacemaker nodig was om alles werkend te krijgen. Vandaar de naam. Omdat Red Hat tot vrij recent een eigen clusteroplossing had, kun je daar de Rgmanager (resource group manager) nog tegenkomen als alternatief voor Pacemaker. Wij behandelen de configuratie van Rgmanager hier verder niet.
Software installatie en configuratie
Voordat je überhaupt de cluster software zelf gaat inrichten, moet je ervoor zorgen dat je cluster servers aan een aantal belangrijke voorwaarden voldoen. We vatten de voorwaarden hieronder kort samen zonder ze uitgebreid te bespreken:
-De cluster nodes moeten in hetzelfde broadcast domain voorkomen. Er mag dus geen router tussen de nodes staan;
-Host name resolving (/etc/hosts of DNS) werkt;
-De cluster nodes zijn aan de zelfde NTP tijdserver verbonden en tijd is gesynchroniseerd;
-Als gedeelde opslag gebruikt gaat worden, is een verbinding met de gedeelde opslag gemaakt;
-Om het eenvoudig te houden (maar niet strikt noodzakelijk) is het goed om beveiligingsmaatregelen zoals SELinux en IPtables uit te zetten;
-Ook is het heel handig als er SSH-keys tussen de cluster nodes uitgewisseld zijn, zodat eenvoudig en geautomatiseerd bestanden tussen de nodes geconfigureerd kunnen worden.
Nadat je al het voorbereidende werk gedaan hebt, kun je de software installeren. De exacte naam van de software onderdelen verschilt natuurlijk tussen de distributies, maar als je ervoor zorgt dat de corosync, pacemaker, hawk en crmshell packages geïnstalleerd zijn, zit je meestal wel goed. Na de installatie van de software packages, begin je ermee om configuratiebestand voor de membership layer aan te maken. Dit bestand heet /etc/corosync/corosync.conf en het heeft een inhoud die eruit moet zien als in figuur 2:
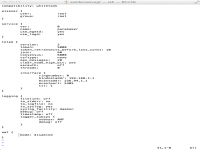
Inhoud van corosync.conf
Vrijwel alles uit figuur 2 kan gewoon overgenomen worden, alleen de instellingen in de interface definitie moeten nog aangepast worden. Bij bindnetaddr moet je het IP adres neerzetten dat gebruikt wordt op de netwerkkaart waarmee je aan het cluster verbindt. Daarnaast moet je bij mcastaddr een multicastadres gebruiken dat uniek is binnen je netwerk. Gebruik bij voorkeur een adres dat begint met 224.0.0, want niet alle multicastadressen doen het in alle omgevingen. Nadat je de aanpassingen gedaan hebt, moet je de service openais (SUSE) of corosync (Red Hat) starten, bijvoorbeeld met de opdracht service openais start.
Nadat je op een node het corosync.conf bestand aangemaakt hebt, gebruik je op die node de opdracht crm_mon. Met deze opdracht bekijk je de huidige status van het cluster. Dat zou er momenteel nog wat eenzaam uit moeten zien, maar als het goed is, zie je dat je een cluster hebt waarin 1 node beschikbaar is.
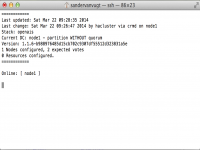
Resultaat van crm_mon
Alles goed gegaan? Maak dan op de andere cluster node ook een corosync.conf aan en start de bijbehorende service. Als ook hier alles goed gaat, laat de opdracht crm_mon nu een cluster zien met daarin twee nodes. Als dit het geval is, kun je verder met de configuratie.
STONITH
Een belangrijk onderdeel van elk cluster is STONITH. Dit is echter ook het onderdeel waarop het vaak verkeerd gaat met de configuratie van het cluster. Het punt is dat je voor STONITH speciale hardware nodig hebt en zeker in testomgevingen is die hardware niet altijd aanwezig. Beheerders denken soms bijdehand te zijn en STONITH om die reden maar gewoon uit te zetten. Echter: zonder STONITH kan de werking van het cluster niet gegarandeerd worden. Zonder STONITH heeft het geen zin een cluster in te richten.
Waar het bij STONITH op neer komt, is dat het cluster met een extern apparaat moet kunnen communiceren om een node hardwarematig uit te zetten als deze niet langer reageert. Hiervoor wordt in het cluster een zogenaamde resource agent aangemaakt. Deze resource agent wordt geconfigureerd om te communiceren met het externe apparaat.
Er zijn verschillende mogelijkheden om externe apparatuur in te zetten voor STONITH. Als je cluster op een virtualisatieplatform draait, kun je STONITH met de hypervisor laten communiceren. Is je server voorzien van een management kaart, zoals HP ILO of Dell DRAC, dan laat je STONITH met de management kaart communiceren. Zo zijn er nog een aantal andere mogelijkheden. In dit artikel maken we gebruik van de Libvirt STONITH agent. Hierbij geeft het cluster aan de hypervisor een instructie om een falende node te stoppen. Het enige wat hier voor nodig is, is dat de public SSH keys van de gebruiker root op de hypervisor beschikbaar moeten zijn in de cluster nodes. De rest van de configuratie vindt plaats vanuit het cluster zelf.
De cluster resources aanmaken
Om cluster resources op een eenvoudige manier aan te maken, is het aan te raden HAWK te gebruiken (HA Web Konsole). Dit is een eenvoudig te gebruiken beheersomgeving waarbij je alles vanuit een browser aanmaakt. Als je uiteindelijk echt serieus aan het werk gaat, ben je beter af met de crm shell, waar je alles in de command line doet. Om er in eerste instantie voor te zorgen dat je eenvoudig een werkende configuratie krijgt, is het aan te raden hawk te installeren.
Nadat je het hawk package geïnstalleerd hebt, start je de service (service hawk start). Dit zorgt ervoor dat de service beschikbaar komt op poort 7630. Voordat je aanmeldt, zorg je er nu voor dat de gebruiker hacluster lid is van de groep hagroup. Voorzie deze gebruiker tevens van een wachtwoord. Start nu een browser naar https://jouserver:7630, negeer de certificaatfout en meld je aan in hawk.
Eenmaal in Hawk klik je in de knoppenbalk links in beeld op Resources. Je ziet nu de resource types die je aan kunt maken. Kies het type Primitive en klik op het + teken om een resource van dit type aan te maken. Geef de resource een naam en kies vervolgens onder Class het type STONITH. Nu selecteer je onder Type het type External/libvirt. Nu moet je aangeven welke parameters deze STONITH resource nodig heeft. Als eerste zijn dat de hosts die beheerd moeten worden en daarnaast is dat de link die nodig is om met de hypervisor te communiceren. Deze URL ziet er voor de KVM STONITH agent wat merkwaardig uit, namelijk qemu+ssh://serveradres/system. Neem gewoon de volledige URL over en zorg ervoor dat het server adres ingevuld staat, dan komt het helemaal goed. Klik tot slot op Create Resource om de resource aan te maken en weg te schrijven naar het cluster.
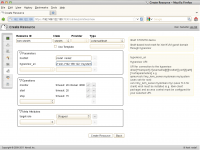
Een STONITH resource aanmaken vanuit Hawk
Als alles goed gaat, wordt de resource meteen toegevoegd aan het cluster en zie je hem met de status “Started” als je vanuit Hawk of vanuit crm_mon kijkt naar de huidige status. STONITH is vaak echter lastig, dus de kans is groot dat je helemaal niets ziet. Als dat het geval is, is het aan te raden om met crm configure edit de cluster configuratie te openen in een editor interface en de eigenschappen van de resource nog eens goed te bekijken.
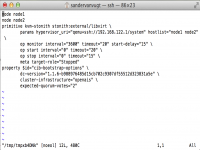
De cluster configuratie bekijken en aanpassen vanuit crm configure edit
Als je nu zorgvuldig naar de code in figuur 5 kijkt, valt misschien op waarom het cluster het niet doet. De primitive kvm-stonith die zojuist is aangemaakt, heeft namelijk de status ‘Stopped’! Nu je dit weet, kun je proberen de resource te starten met de opdracht crm resource start kvm-stonith. Als alles goed gaat, zie je dat de resource nu ergens in het cluster gestart wordt.
Nu de STONITH resource operationeel is, wordt het tijd om een resource aan te maken voor de Apache service. Deze resource moet uit 3 onderdelen bestaan: een IP-adres, een file system en tot slot de Apache service zelf. Het IP adres is nodig voor de gebruiker om contact te maken met de Apache service. Een geclusterde service zal namelijk de ene keer op de ene node en de andere keer op een andere node draaien. De IP-adressen van de nodes kunnen dus niet gebruikt worden om de service te benaderen. Daarom krijgt de service een apart virtueel IP-adres.
Vervolgens is er een file system nodig voor de Apache Documentroot. Het is immers zaak dat Apache altijd bij zijn documenten kan, ongeacht de node waar de service op dat moment toevallig op draait. Dit regel je door een partitie of logisch volume aan te maken op het SAN en dat door het cluster te laten mounten op de node waar de Apache service op dat moment draait. In het onderstaande voorbeeld maken we hiervoor gebruik van een partitie die voor dit doel op het SAN is aangemaakt en geformatteerd met het XFS bestandssysteem. Let er wel goed op dat de SAN schijf op beide nodes in het cluster beschikbaar moet zijn! Tot slot is er de Apache service zelf die door het cluster gestart wordt.
Je kunt alle resources aanmaken vanuit de Hawk Resource management optie. Maak om te beginnen het IP adres. In figuur 6 zie je welke waarden je hiervoor moet selecteren en invoeren.
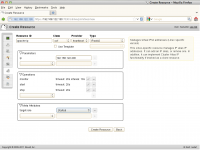
Configureren van het geclusterde IP adres
Maak nu, wederom vanuit Hawk het filesystem aan. In figuur 7 zie je de opties die daarvoor gebruikt moeten worden. Let vooral op de naam van je gedeelde disk, deze is namelijk sterk afhankelijk van de gebruikte configuratie. Tot slot maak je ook de Apache service aan. Zie figuur 8 voor de te gebruiken parameters.
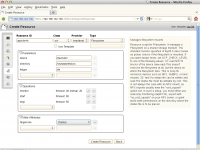
Het geclusterde bestandssysteem
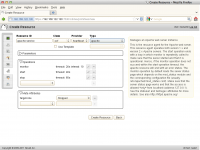
De geclusterde Apache service
Als je nu kijkt in crm_mon, zie je waarschijnlijk dat alle resources wel draaien, maar niet op dezelfde node. Dat werkt natuurlijk niet en daarom is het nu zaak om een group aan te maken. Door een group te definiëren in het cluster, bepaal je de volgorde waarin de services gestart worden en zorg je er tevens voor dat de resources altijd op dezelfde node draaien. We doen dit voor de verandering met de opdracht crm configure edit. Voeg in de configuratie een nieuwe regel toe die er als volgt uit ziet:
group apache-group apache-ip apache-fs apache-service
Type nu de opdracht crm resource cleanup apache-group en kijk nog eens in crm_mon. Je zult als alles goed gegaan is de groep netjes zien draaien, met alle resources op dezelfde node. Gefeliciteerd, je hebt zojuist je eerste cluster gemaakt!
Nawoord
Het aanmaken van een cluster is specialistenwerk. Afhankelijk van de omgeving waarin het cluster gebruikt wordt, kun je tegen heel veel zaken aanlopen die daar net iets anders geregeld moeten worden. De basis is echter niet echt moeilijk, zoals je in dit artikel hebt kunnen lezen.