Logfiles vind je terug op elke Linux-server, van een Raspberry Pi in de meterkast tot servers van ettelijke tienduizenden euro’s in een datacenter. Ze zijn onmisbaar om problemen op te lossen, maar veroorzaken niet zelden zélf problemen. Als de logfiles te snel groeien en daardoor een filesystem volloopt, riskeren bepaalde programma’s niet meer correct te draaien. Denk dus goed na over het beheer van je logfiles!
Voor logfiles moet je natuurlijk een bepaalde hoeveelheid opslagruimte voorzien. Hoeveel dat precies is, hangt af van de activiteit op de server en de gewenste bewaringstermijn. Het spreekt voor zich dat 30 dagen aan logs op een proxyserver met duizenden actieve gebruikers heel wat meer ruimte inneemt dan 7 dagen aan logs op een webserver met slechts enkele honderden bezoekers per dag. Vergeet in elk geval niet om logrotate correct te configureren. Met logrotate splits je de logs netjes per dag op, comprimeer je de vorige logfiles (dat bespaart al heel wat ruimte!) en verwijder je de oudste logs. In principe is logrotate actief voor alle software die je via de package manager installeert. Toch kan het geen kwaad om de configuratie eens na te kijken. Heb je met name de logging van bepaalde programma’s aangepast, dan is het mogelijk dat logrotate sommige logfiles niet meer herkent. Of misschien wil je wel enkele specifieke logs minder lang of net langer bewaren?
Grenzen stellen
Mocht het onverwacht toch mislopen, dan wil je de impact natuurlijk zo beperkt mogelijk houden. Schrijft één daemon het /var-filesystem vol met een logfile, dan kan je systeem rare kuren beginnen te vertonen. Alle andere daemons kunnen dan immers ook niet meer loggen in /var/log of tijdelijke bestanden aanmaken in /var/tmp, /var/cache, enzovoorts. Het is dus geen slecht idee om bijvoorbeeld een apart filesystem aan te maken voor /var/log of zelfs voor de logs van één bepaalde service, zoals /var/log/squid voor de Squid-proxyserver.
Draait elke service netjes onder zijn eigen gebruiker (zoals het hoort!), dan kun je bijvoorbeeld ook met quota per gebruiker werken. Onder normale omstandigheden mogen de services natuurlijk geen last ondervinden van de ingestelde quota. Loopt er toch iets mis, dan is de schade tenminste beperkt tot één service. Als alternatief kun je de logfiles van alle systemen naar één centrale logserver sturen. Dat maakt het beheer van de beschikbare ruimte voor logs alvast een stuk eenvoudiger!
Snel inkorten
Maar wat doe je nu als het /var-filesystem door een logfile is volgelopen en je zo snel mogelijk de services wilt herstellen? De logfile leegmaken (met > logfile) is veruit de snelste oplossing, maar dan weet je natuurlijk ook niet waarom die zo groot is geworden! De logfile verplaatsen of comprimeren (op een andere locatie) is een optie, maar dat kan wel even duren voor grote logfiles én je moet ook elders de nodige schijfruimte hebben. In zulke gevallen is het handig om de logfile in te korten tot een bepaalde grootte. Stel dat de logfile bijvoorbeeld 2GB is geworden, en je slechts 200MB wilt behouden. Met truncate kort je dat bestand in tot 200MB:
$ truncate -s 200M logfile
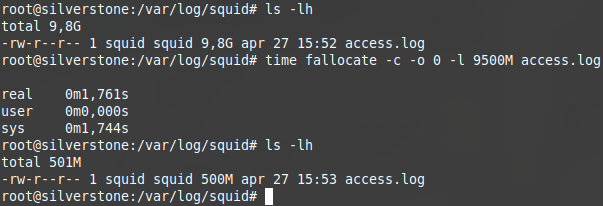
Helaas knipt truncate data weg aan het einde van het bestand, terwijl bij logfiles vooral de meest recente data interessant is. Om data aan het begin weg te knippen, kun je (althans op xfs- en ext4-filesystems) terugvallen op fallocate’s collapse-range-optie. Terwijl je bij truncate de resterende bestandsgrootte aangaf, moet je bij fallocate aangeven hoeveel data je wilt wegknippen:
$ fallocate -c -o 0 -l 1800M
Zo maak je in slechts enkele seconden extra schijfruimte vrij zónder de laatste logentries te verwijderen!