Als je een Linux server draait, dan is het belangrijk om te controleren dat die server de prestaties biedt, die je nodig hebt. Dat kan je voor een heel groot deel doen door gebruik te maken van tools zoals top, maar op een gegeven moment kom je daar niet echt veel verder meer mee. Dit artikel beschrijft tools en methodes, die je toe kunt passen als je meer details nodig hebt waarom je server het niet doet.
Om Linux performance te analyseren, beperken veel beheerders zich door enkel te kijken naar wat het besturingssysteem weergeeft over de huidige status van de performance van Linux. Deze manier van kijken geeft een redelijk beeld van wat er gaande is, maar vertoont ook de nodige tekortkomingen. De leading tool voor een dergelijke performance analyse is top.
Als je als beheerder niet verder kijkt dan top, zul je in veel gevallen wel een probleem kunnen waarnemen, maar het nooit echt op kunnen lossen. Nadat je geconstateerd hebt dat je een probleem hebt (“mijn CPU is voor 100% belast”), wordt het tijd om echt te analyseren wat er aan de hand is. Hiervoor moet je om te beginnen weten welke toepassing het probleem veroorzaakt. Dit is vaak eenvoudig te achterhalen met tools als top. Ben je eenmaal op de hoogte welke applicatie die overlast veroorzaakt, dan wordt het zaak om dieper te gaan kijken.
Profiling en tracing
Om te achterhalen wat er precies gebeurt op applicatieniveau, kan gebruikgemaakt worden van profiling of tracing. Bij profiling gaat het erom om op een slimme wijze te achterhalen wat een applicatie aan het doen is. Bij tracing wordt op een grovere wijze geanalyseerd wat een toepassing precies doet. Een bekende tool die ingezet wordt voor tracing is strace. Type bijvoorbeeld maar eens:
strace ls
om te zien dat de gegevens die met tracing geproduceerd worden niet altijd heel inzichtelijk zijn (zie figuur 2).

Met tracing is het soms lastig om de relevante informatie terug te vinden.
Één van de meest nuttige commando’s op het gebied van profiling is perf. Deze tool werkt op basis van evenementen, die op verschillende punten gegenereerd worden. Deze evenementen worden bijvoorbeeld bijgehouden door de Performance Monitoring Unit in the processor. Daarnaast kan performance informatie gehaald worden uit software en drivers, die tracepoints en gegevens bij kunnen houden over verschillende soorten software evenementen.
Om een tool als perf goed te kunnen gebruiken, is echter wel het nodige voorwerk nodig. Om te beginnen moet je vaak extra software installeren voor de toepassing die je wilt tracen. Voor heel veel toepassingen zijn er packages beschikbaar met tracing informatie. Als die eenmaal geïnstalleerd zijn, kunnen specifieke software events getraceerd worden. Je moet je echter wel realiseren dat er een significante prijs is, die je hiervoor betaalt. Om een succesvolle trace te kunnen uitvoeren, is het nodig om extra zaken te installeren, die in eerste instantie het performanceprobleem alleen maar groter zullen maken. Het is dus zaak de applicatie tracing te doen op een server, die geen productie draait.
Werken met perf
Om een toepassing (driver of hardware) te kunnen tracen, moet je eerst weten welke events er allemaal beschikbaar zijn. Dit doe je met de opdracht:
perf list
***
Deze opdracht toont een lange lijst met evenementen. Deze eventnamen heb je nodig om een gericht onderzoek uit te voeren. Dit is bepaald geen sinecure, want vaak is er diepgaand inzicht nodig in de werking van de hardware en Linux kernel om in te kunnen schatten wat het effect is van het gebruik van een bepaald tracepoint.
Met trace list toon je een lijst van beschikbare tracepoints
Als je dan weet wat je wilt tracen, kun je dit tracepoint gaan monitoren met perf record. Hiermee zet je als het ware een plug op een bepaald tracepoint en alle informatie die daaruit voortkomt, wordt weggeschreven naar een databestand. Dit bestand wordt aangemaakt in de huidige directory en heeft de naam perf.data. Type bijvoorbeeld:
perf record -e LLC-loads ls
om te achterhalen hoe vaak het voorkomt dat er iets in cache geladen moet worden, zodat de opdracht ls zijn werk kan doen. Je zult niet direct zien wat het resultaat is van dit commando. Dat bekijk je met:
perf report
Dit commando toont standaard de inhoud van het laatste perf.data bestand dat is aangemaakt. Figuur 4 toont hoe zo’n rapport eruit ziet.
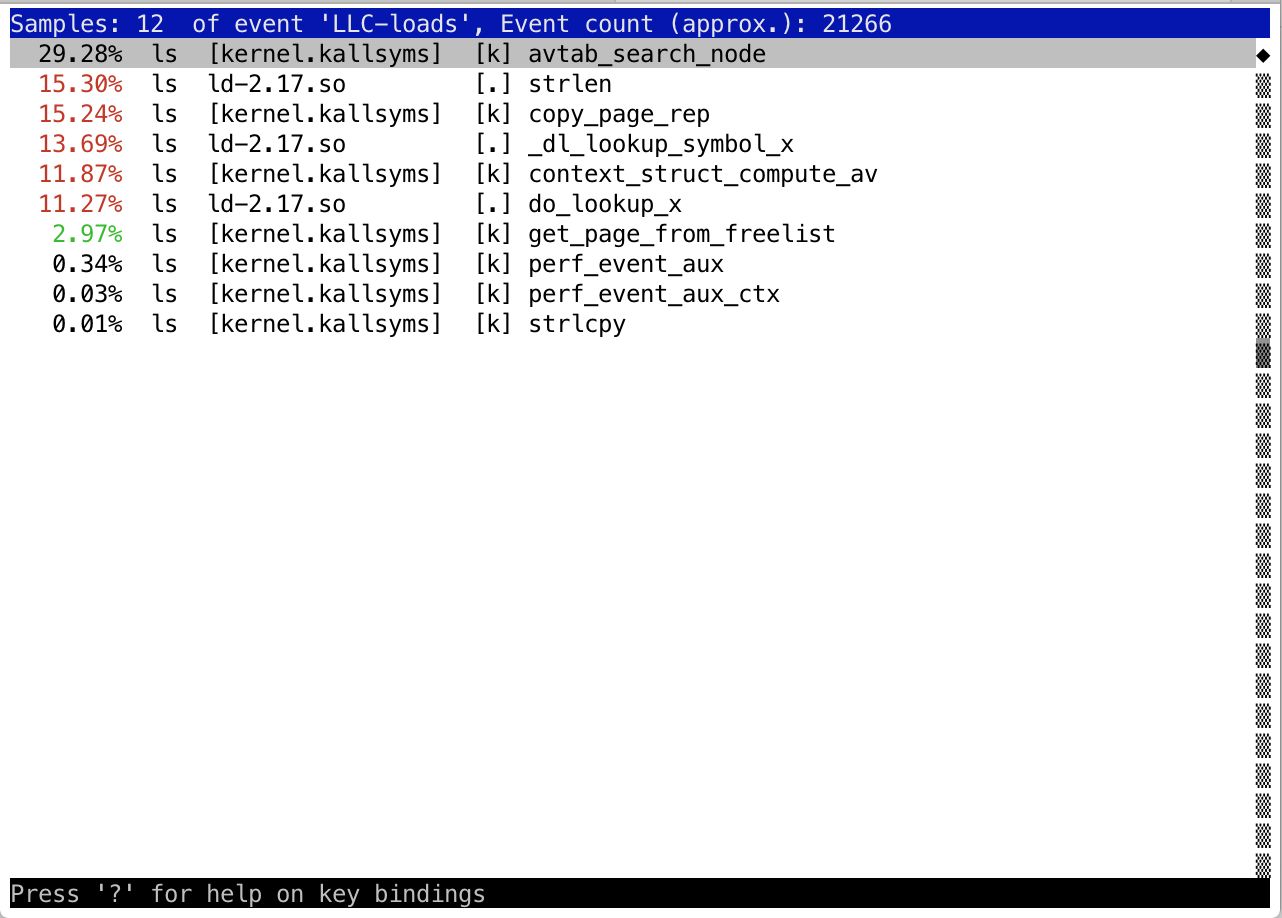
Figuur 4: Perf data analyseren met perf report.
In perf report zie je precies weergegeven hoe de belasting is voor het tracepoint, dat je hebt opgegeven. Als je kijkt naar figuur 4, zie je dat voor het event LLC-loads de resultaten in kolommen weergegeven worden. De eerste kolom toont de belasting en in de 2e kolom zie je het commando dat je getraced hebt. De derde kolom toont vervolgens welke system call in kernel space, of library call in user space hiervoor gebruikt werd. Hierachter worden nog wat meer gegevens getoond over wat er dan precies gedaan is. Je zult ook zien dat dit informatie betreft, die ver voorbij gaat aan wat de meeste systeembeheerders regelmatig in hun werk tegenkomen. Het gaat hier om informatie waarmee je naar de ontwikkelaar van de toepassing kunt stappen om duidelijk aan te geven wat er precies mis gaat met zijn toepassing in een bepaalde serveromgeving.
Juist voor die ontwikkelaar is perf een zeer waardevolle tool. Met perf zie je namelijk niet alleen wat een bepaalde system call gedaan heeft, maar wordt regel na regel heel precies duidelijk gemaakt welke stappen er binnen een system call, library call of wat dan ook zijn uitgevoerd. In perf report wordt deze informatie ontsloten door een regel te selecteren en vervolgens op Enter te drukken.
In essentie komt het er bij het werken met perf op neer dat je uit gaat pluizen wat een toepassing precies doet. Er is ook een andere manier om de tool in te zetten. Als je bijvoorbeeld gewoon:
perf top
typt, krijg je in een top-achtige interface te zien welke tracepoints het meest gebruikt worden (zie figuur 5). Daarbij kan het ook voorkomen dat je meldingen krijgt, dat er geen symbols beschikbaar zijn voor een bepaalde toepassing. Zoals eerder gezegd: om zinnige dingen te kunnen doen met perf, heb je debugging informatie nodig en daarvoor zul je in een aantal gevallen extra debug packages moeten installeren.
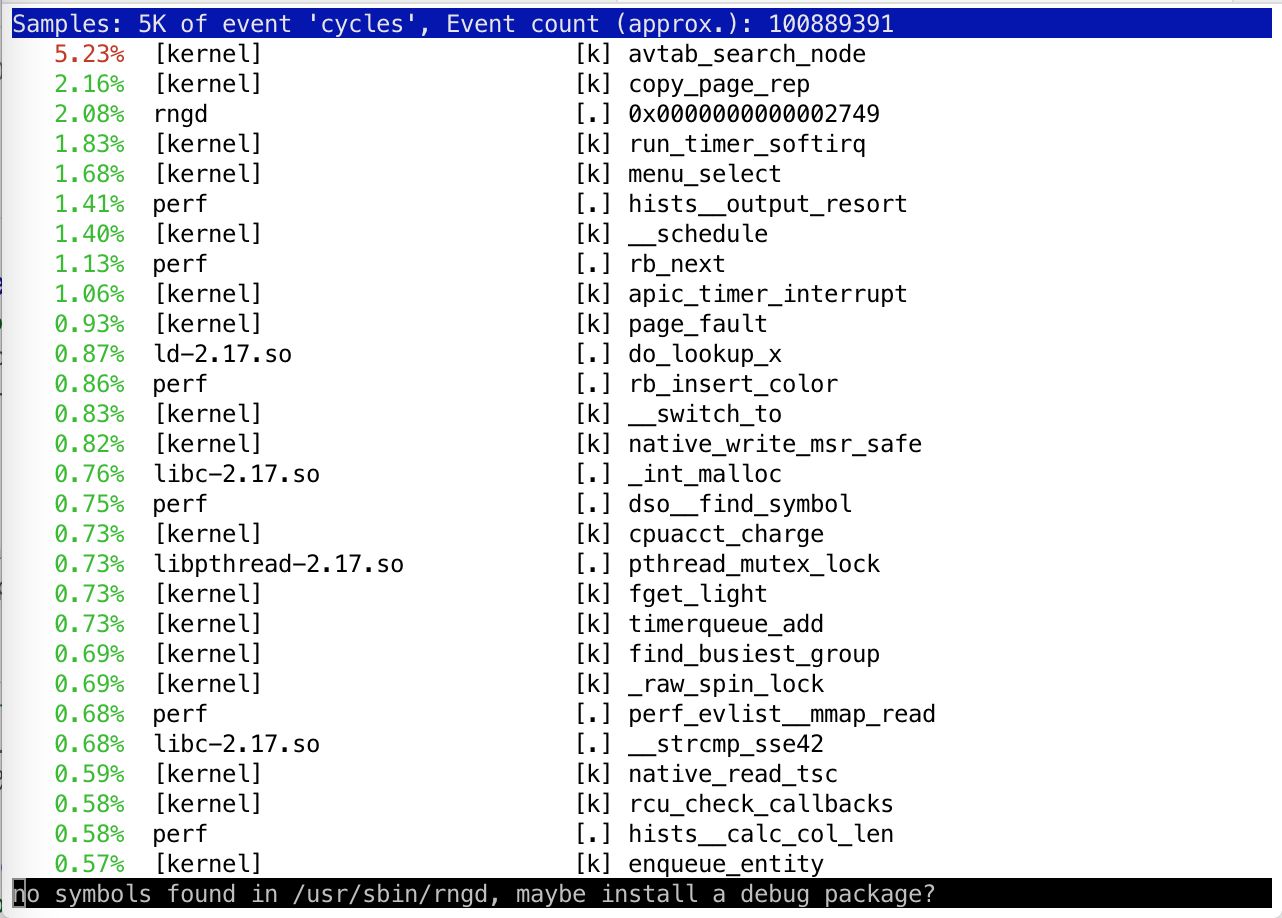
Figuur 5: perf top geeft inzicht in de meest actieve tracepoints
Het mag duidelijk zijn: perf is een tool die je niet zomaar voor de grap laat draaien in de hoop dat je wat meer duidelijkheid krijgt over activiteit op je systeem. Perf wordt ingezet door beheerders, die heel nauwkeurig moeten analyseren wat er binnen een toepassing gebeurt, om op basis daarvan heel doelgericht te kunnen optimaliseren wat er mis is met een systeem. Dit is een veel intelligentere methode dan te proberen op goed geluk sysctl parameters in de Linux kernel aan te passen. Het brengt echter flink wat extra werk met zich mee…