
In Linux Magazine 5 van 2021 las je een workshop over geautomatiseerde beeldbewerking in Python. Je leerde er onder andere afbeeldingen verkleinen, roteren en bijsnijden. Jammer genoeg maakt onze voorbeeldcode slechts gebruik van één CPU core. In deze korte workshop lossen we dat probleem op!
Filip Vervloesem
Mocht je de workshop over Pillow niet meteen bij de hand hebben, dan is dat geen probleem. We hebben het script nog een beetje aangepast om als basis te dienen voor deze workshop. Zo moesten we de code om de afbeeldingen te verwerken in een functie plaatsen en hebben we wat extra code toegevoegd om met de time-module de verwerkingssnelheid van het script te berekenen en te tonen. Het script ziet er nu als volgt uit:
import os, sys, time
from PIL import Image
def verklein(invoer):
map, bestand = os.path.split(invoer)
uitvoer = 'output/' + bestand
try:
with Image.open(invoer) as afbeelding_in:
if afbeelding_in.width > afbeelding_in.height:
afmetingen = (1920, 1285)
bijsnijden = (0, 105, 1920, 1185)
else:
afmetingen = (1285, 1920)
bijsnijden = (105, 0, 1185, 1920)
afbeelding_verkleind = afbeelding_in.resize(afmetingen)
afbeelding_bijgesneden = afbeelding_verkleind.crop(bijsnijden)
afbeelding_bijgesneden.save(uitvoer, exif=afbeelding_in.info.get('exif'), quality='web_high')
except OSError:
print('Fout bij het verwerken van bestand', invoer)
bestanden = sys.argv[1:]
aantal_bestanden = len(bestanden)
start = time.time()
for bestand in bestanden:
resize(bestand)
einde = time.time()
tijd = einde - start
snelheid = aantal_bestanden / tijd
print(f'{aantal_bestanden} bestanden verwerkt in {tijd:.1f} seconden ({snelheid:.1f} bestanden per seconde)')
Kopieer en plak deze Listing rechtstreeks vanaf linuxmag.nl!
Een eerste test
Het script start je als volgt op de commandline om alle afbeeldingen in één bepaalde map te verwerken:
$ python3 thumbnail.py input/*.JPG
De uitvoer van het script vind je nadien terug in de map ‘output’. In ons voorbeeldscript zullen we alle afbeeldingen verkleinen (en bijsnijden) tot een resolutie van 1920 bij 1080 pixels of 1080 bij 1920 pixels (afhankelijk van de oriëntatie). Vervolgens bewaren we de afbeelding in het JPEG-formaat, geoptimaliseerd voor gebruik op het web. Het resultaat van een eerste test op 50 tien-megapixel foto’s zie je in Afbeelding 1. Met een verwerkingssnelheid van net geen twee afbeeldingen per seconde moeten we 26 seconden wachten om alle afbeeldingen te verkleinen. Dat lijkt nog niet zo erg. Maar als je thuiskomt met 1000 foto’s van je vakantie, ben je dus wel bijna negen minuten aan het wachten om die te verkleinen. En dan hebben we zelfs afbeeldingen van slechts 10 megapixels gebruikt in onze test!

Extra CPU cores
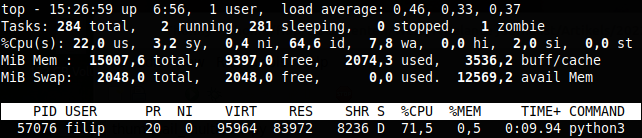
Hedendaagse computers beschikken bijna altijd over meer dan één CPU core. Voor chipfabrikanten bleek dat makkelijker en goedkoper te zijn dan enkel de kloksnelheid te verhogen om beter presterende CPU’s te ontwikkelen. Jammer genoeg moet de software dat ook wel ondersteunen. Programma’s moeten dus aangepast worden om die extra rekencapaciteit te benutten. Dat geldt uiteraard ook voor Python scripts die jij schrijft. Start maar eens het topprogramma in een ander terminalvenster, terwijl jouw script aan het draaien is. Je krijgt dan wellicht een soortgelijke uitvoer te zien als in Afbeelding 2. Het python3-proces gebruikt ongeveer 70% van de CPU-capaciteit (zie de onderste regel). Maar let op: 100% staat gelijk aan de maximale capaciteit van één CPU core. Op ons testsysteem, met vier cores, zouden we dus tot 400% kunnen gaan. Dat zie je ook duidelijk in de derde regel van de topuitvoer. Achter %Cpu(s) staat 22,0 us, ofwel 22% van de totale CPU-capaciteit wordt door user processes gebruikt. Met andere woorden: drie van de vier CPU-cores worden absoluut niet gebruikt. Dat kan beter!
Threads of processen?
Zoek je informatie over het benutten van meerdere CPU cores in Python, dan kom je al snel de termen ‘multithreading’ en ‘multiprocessing’ tegen. Er bestaat dan ook meer dan één manier om verschillende taken tegelijk in Python te draaien. Kort door de bocht gebruik je multithreading als de verschillende taken afhankelijk zijn van elkaar en multiprocessing als ze echt volledig gelijktijdig mogen lopen. Vooral multithreading is geen eenvoudige materie, maar voor ons is dat geen probleem. Het verwerken van grote hoeveelheden bestanden is immers een prima voorbeeld waarbij elke deeltaak (één bestand verwerken) compleet onafhankelijk is van de andere taken. Wij gaan dus aan de slag met multiprocessing. De eerste vraag is natuurlijk hoeveel processen we tegelijkertijd willen draaien? Het antwoord is eenvoudig: zoveel als het aantal CPU cores in ons systeem. Dat aantal vraag je als volgt op in Python:
aantal_cores = os.cpu_count()
Multiprocessing
Om de multiprocessing-functionaliteit in te schakelen, laad je de volgende module aan het begin van jouw Python script:
from concurrent.futures import ProcessPoolExecutor
Verwijder eerst de eenvoudige for-loop waarin we alle bestanden één voor één verwerken. In plaats daarvan maak je een ProcessPoolExecutor-object aan om evenveel taken als het aantal CPU cores parallel te starten:
pool = ProcessPoolExecutor(max_workers=aantal_cores)
Vervolgens bepaal je nog welke functie met welke bestanden je wil starten in die pool:
list(pool.map(resize, bestanden))
Start het script nu opnieuw met dezelfde invoerbestanden en vergelijk de uitvoer met de eerste versie. Op ons testsysteem zagen we dat de verwerkingssnelheid nu ongeveer een factor drie hoger ligt (6.1 in plaats van 1.9 bestanden per seconde). In principe mag je met vier cores natuurlijk verwachten dat het viermaal sneller gaat. Maar bij de relatief kleine bestanden uit onze test neemt de overhead van het starten van de processen een aanzienlijk deel van de tijd in. De CPU cores krijgen dus onvoldoende opdrachten binnen om altijd aan 100% te werken. Wil je dat vermijden? Experimenteer dan met een hoger aantal cores dan het werkelijke aantal in jouw systeem, bijvoorbeeld:
aantal_cores = int(os.cpu_count() * 1.5)
Met bovenstaande aanpassing kregen we een verwerkingssnelheid van rond de 7.5 bestanden per seconde: inderdaad bijna viermaal zo snel als onze eerste versie!
Voortgangsbalk
Het script is nu weliswaar heel wat sneller, maar de precieze voortgang blijft onduidelijk. Je krijgt pas aan het einde van het script te zien hoeveel bestanden er verwerkt zijn en hoelang dat duurde. Daarom kijken we nog even snel hoe je een mooie voortgangsindicator kunt toevoegen. Dankzij de tqdm-module hoef je daarvoor niet meer zelf aan de slag. Sinds versie 4.42 heeft die immers expliciet ondersteuning voor de concurrentmodule, waardoor het erg makkelijk is om de voortgang van alle processen op te volgen. Installeer tqdm wel best via pip of vanuit Thonny, want jouw distributie bevat mogelijk nog een oudere versie zonder die functionaliteit. Je mag de importregel voor de concurrent.futures-module nu vervangen door:
from tqdm.contrib.concurrent import process_map
En de twee regels code uit de vorige paragraaf door:
resultaat = process_map(verklein, bestanden, max_workers=aantal_cores, desc="Afbeeldingen verkleinen", unit="bestanden")
Ook de code om de start- en eindtijd te berekenen is nu overbodig. Het uiteindelijke script én de uitvoer ervan zie je in de afbeeldingen op deze pagina. Dat ziet er al heel wat netter uit dan de eerste versie van ons script, nietwaar?
![]()
De voortgangsbalk van het script.