In vijf minuten een webserver met configuratiebeheer
Ansible is een opensource configuratiebeheersysteem van Red Hat. Veel bedrijven gebruiken het om hun serverpark te beheren. Maar ook voor thuisgebruik is het een prima oplossing, bijvoorbeeld voor je webserver, NAS en Raspberry Pi’s.
Auteur: Koen Vervloesem | Gepubliceerd in Linux 2 2021
Als je een server configureert, wil je dat zo weinig mogelijk manueel doen. Want als je server het laat afweten, wil je die zo snel mogelijk opnieuw configureren in dezelfde toestand, in plaats van allerlei opdrachten in de shell te moeten intypen. En als je tien servers met dezelfde configuratie hebt draaien, wil je echt de garantie dat ze allemaal effectief dezelfde configuratie hebben.
Ansible
Om dat te bereiken, gebruik je een configuratiebeheersysteem, zoals Ansible. Hiermee configureer je je servers in YAML-bestanden die beschrijven in welke toestand je servers zich moeten bevinden. Die YAML-bestanden vormen samen een playbook, dat je toepast op je servers. Het leuke aan Ansible is dat je daarvoor op je servers geen speciale software hoeft te installeren. Er moet alleen Python op staan en er moet een SSH-server draaien. Je kunt met Ansible dan ook allerlei Linux- of Unix-systemen (en zelfs Windows) beheren, van een Raspberry Pi of een router tot een webserver.
Aan de slag
Belangrijk om te weten is dat je de Ansible-configuratie niet op je doelmachines zet, maar op je werkstation. Daar installeer je Ansible ook en voer je het uit, waarna de configuratie via ssh naar je doelmachines wordt gepusht. Installeer dus eerst Ansible, bijvoorbeeld met Pythons pakketbeheerder pip:
pip3 install ansible
Maak dan een directory voor je Ansible-configuratie aan. In dit artikel creëren we een voorbeeldconfiguratie om een webserver te installeren:
mkdir website cd website
Inventory
Maak nu een bestand inventory aan, waarin je de webserver(s) definieert. Bijvoorbeeld:
[webservers] www1.example.com www2.example.com
Standaard logt Ansible op de servers in met dezelfde gebruikersnaam als degene waarmee je op je werkstation Ansible uitvoert. Die gebruiker kun je aanpassen in je inventory:
www3.example.com ansible_user=foobar
Zorg nu dat Ansible via ssh met die gebruikersnaam kan inloggen op de server. Dat kun je bijvoorbeeld doen door een publieke sleutel met ssh-copy-id naar de server te kopiëren.
Test je verbinding
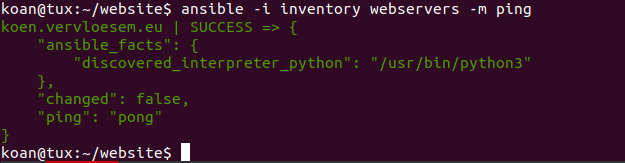
Daarna kun je eenvoudig testen of Ansible verbinding kan maken met de servers in je inventory en een opdracht kan uitvoeren:
ansible -i inventory webservers -m ping
Je zou voor elke server in je inventory een melding SUCCESS moeten zien met wat JSON-gegevens. De ping-module is verder niet zo nuttig, maar wel handig om te testen of je servers aan de basisvereisten voor Ansible voldoen. Als je de optie -m ping weglaat, voert Ansible standaard de module command uit. Zo kun je een willekeurige opdracht op je servers uitvoeren met de optie -a, bijvoorbeeld om het schijfverbruik van je webservers te bekijken:
ansible -i inventory webservers -a "df -h"
Dit is een handige manier om dezelfde opdracht tegelijk op een boel servers uit te voeren en hun uitvoer te vergelijken.
Caddy installeren
Laten we onmiddellijk iets nuttigers doen: de webserver Caddy op een Ubuntu-server installeren. Maak daarvoor een YAML-bestand site.yml aan met de volgende inhoud:
--- - hosts: webservers tasks: - name: Add Caddy repository apt_repository: repo: deb [trusted=yes] https://apt.fury.io/caddy/ / state: present filename: caddy-fury - name: Install Caddy apt: name: caddy
Je ziet dat we hier voor de hosts webservers een lijst met taken definiëren. Die webservers is de groep computers die je in de inventory gedefinieerd hebt.
Daarna komen twee taken, die elk een naam hebben en een module met parameters. De eerste is een taak van de module apt_repository. Daarmee voegen we de repository van Caddy toe. De repository die we aan de parameter repo toekennen, komt te staan in het bestand /etc/apt/sources.list.d/caddy-fury.list. Standaard ververst deze module overigens de apt cache (sudo apt update) op het einde. In de volgende taak van de module apt kunnen we dan ook het pakket caddy installeren. Dit is het begin van je Ansible-playbook. Je voert het als volgt uit op al je webservers:
ansible-playbook -i inventory site.yml
Ansible logt nu op al je webservers in, voegt de repository van Caddy toe en installeert dan Caddy.
Vereisten voor de taken
Op een vers geïnstalleerde Ubuntu-server zal het bovenstaande playbook niet gelukt zijn, omdat het pakket apt-transport-https nodig is om een repository met https toe te voegen. Dat kunnen we natuurlijk gewoon als extra taak toevoegen. Maar zulke basistaken die waarschijnlijk ook voor andere taken nodig zijn, kun je voor de duidelijkheid beter in pre_tasks zetten:
pre_tasks: - name: Ensure apt https transport exists apt: name: apt-transport-https update_cache: true
Alle taken in pre_tasks worden uitgevoerd voordat de taken in tasks aan de beurt komen. Dit is dus de perfecte plaats om basiszaken in orde te brengen. Merk op dat we bij de module apt de parameter update_cache: true zetten om de apt cache te verversen voordat we het pakket apt-transport-https installeren. Zo zorgen we in het begin van ons playbook al dat alle pakketinstallaties erna op een ververste cache gebeuren.
Voer je nu het playbook opnieuw uit, dan werkt alles wel. De https-transport wordt toegevoegd, de repository van Caddy wordt toegevoegd, en uiteindelijk wordt Caddy zelf geïnstalleerd. Merk op: als je het playbook daarna nog eens uitvoert, gebeurt er niets maar krijg je de melding dat er niets veranderd is. Alle modules van de kern van Ansible zijn dan ook idempotent: ze twee keer uitvoeren heeft hetzelfde effect als ze één keer uitvoeren.
Configuratiebestand
We hebben Caddy nu geïnstalleerd, maar de webserver heeft ook een configuratiebestand nodig. Dat maken we met de volgende taken aan:
- name: Set permissions on Caddy config directory file: path: /etc/caddy state: directory owner: root group: root mode: '0755' - name: Copy Caddy config file template: src: Caddyfile.j2 dest: /etc/caddy/Caddyfile owner: root
We zorgen dus dat er een directory /etc/caddy bestaat met de juiste gebruikersrechten, en kopiëren daarin een bestand Caddyfile waarvan de inhoud gebaseerd is op het sjabloon Caddyfile.j2. Dat sjabloon Caddyfile.j2 zet je in de subdirectory templates van je project, waar Ansible naar sjablonen zoekt.
Variabelen
Voordat we de inhoud van het sjabloon bekijken, moeten we het even over variabelen hebben. We kopiëren immers niet zomaar een configuratiebestand voor de webserver, maar passen de inhoud ervan aan op basis van variabelen per server, zoals de hostname en het e-mailadres van de beheerder. Ansible laat je toe om op heel wat plaatsen variabelen in te stellen. Variabelen die voor een hele groep gelden, stel je bijvoorbeeld in een bestand onder group_vars in, zoals in group_vars/webservers voor de groep webservers. Daarin stel je bijvoorbeeld de website root in:
--- # Location where to install web sites www_root: "/var/www"
De domeinen die je op een webserver wilt hosten, zet je in een variabele specifiek voor een host, in host_vars/www1.example.com:
---
# Web sites
www_sites:
- { domain: "www1.example.com", email: "webmaster@example.com" }
- { domain: "www2.example.com", email: "webmaster@example.com" }
Sjablonen
Het sjabloon voor het configuratiebestand van Caddy kan er dan als volgt uitzien:
{% for site in www_sites %}
{{ site.domain }} {
root * {{ www_root }}/{{ site.domain }}/public
file_server
encode zstd gzip
log {
output file {{ www_root }}/{{ site.domain }}/logs/access.log {
# Keep rolled log files for 30 days
roll_keep_for 720h
}
format single_field common_log
}
tls {{ site.email }}
header Strict-Transport-Security max-age=31536000;
header Content-Security-Policy "default-src 'none'; script-src 'self'; connect-src 'self'; img-src 'self'; style-src 'self';base-uri 'self';form-action 'self'"
header X-Frame-Options SAMEORIGIN
header X-Content-Type-Options nosniff
header Referrer-Policy no-referrer-when-downgrade
header Feature-Policy "camera 'none'; geolocation 'none'; microphone 'none'"
}
{% endfor %}
Je ziet hier de variabele www_sites terugkomen. Met {% for site in www_sites %} (dit is de sjabloontaal Jinja) creëren we een lus die alle elementen in st lijst www_sites afgaat. De variabele {{ site.domain }} verwijst dan naar het element domain in een element in die lijst, wat overeenkomt met www1.example.com. Op dezelfde manier verwijzen we naar het opgegeven e-mailadres met {{ site.email }}.
Zaken die tussen {% %} of `{{ }}“ staan worden dus als Jinja-expressies geëvalueerd op basis van de opgegeven variabelen, en de rest wordt letterlijk overgenomen. Zo creëert Ansible met de template-module een configuratiebestand op maat van de server.
Handlers
Als je dit nu zou uitvoeren, zou het configuratiebestand wel aangemaakt worden, maar we moeten er nog voor zorgen dat Caddy automatisch dit inleest, ook als hij al draait. Daarvoor hebben we een handler nodig. Maak daarvoor een bestand handlers/caddy.yml met de volgende inhoud:
--- - name: reload caddy service: name: caddy state: reloaded
En voeg aan de taak die het configuratiebestand aanmaakt een notify parameter toe die ervoor zorgt dat deze handler wordt uitgevoerd als het bestand verandert:
- name: Copy Caddy config file template: src: Caddyfile.j2 dest: /etc/caddy/Caddyfile owner: root notify: reload caddy
In je site.yml verwijs je nog naar je bestand met handlers:
handlers: - import_tasks: handlers/caddy.yml
Wat meer overzicht
We voegen ook nog een taak toe die ervoor zorgt dat Caddy altijd opgestart is, ook als die om een andere reden is gestopt:
- name: Make sure Caddy starts service: name: caddy state: started enabled: true
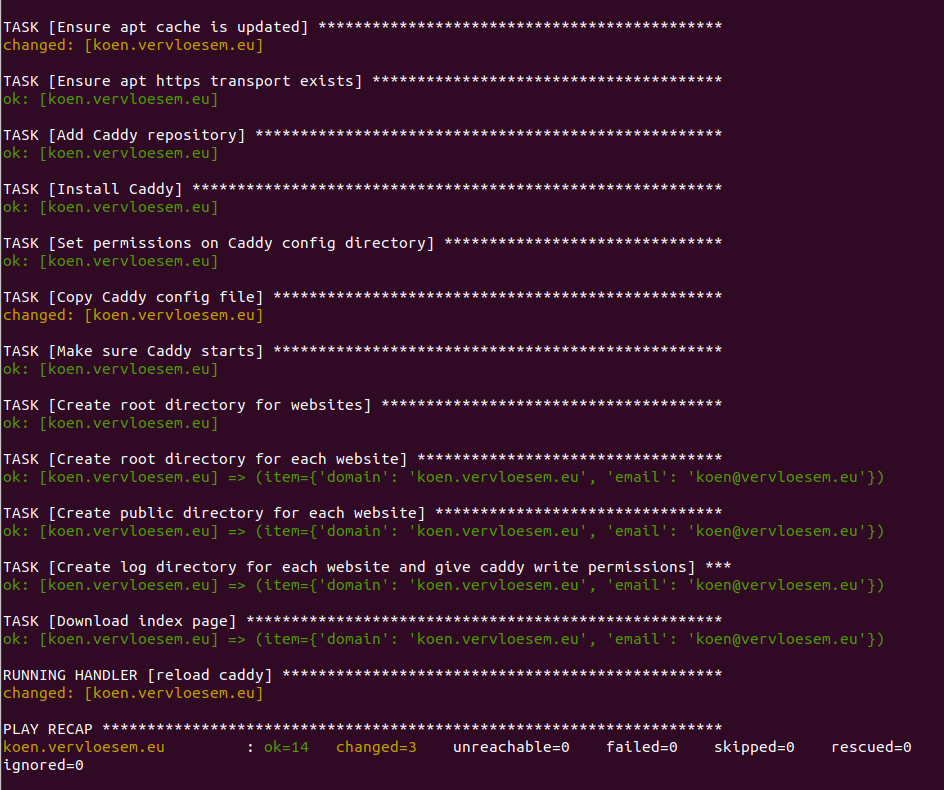
We kunnen nu ook nog wat taken toevoegen om de directory’s aan te maken waarin Caddy de websites verwacht en de logs aanmaakt. Maar we hebben ondertussen al zoveel taken dat we hier beter wat structuur aan geven. Verplaats alle vorige taken uit site.yml naar tasks/caddy.yml, en verwijs daarnaar in site.yml, samen met het nieuwe bestand met taken voor de directory’s:
tasks: - name: Set up Caddy import_tasks: tasks/caddy.yml - name: Create directory tree for websites import_tasks: tasks/webdirs.yml
Die laatste geef je dan de volgende inhoud:
- name: Create root directory for websites
file:
path: "{{ www_root }}"
state: directory
- name: Create root directory for each website
file:
path: "{{ www_root }}/{{ item.domain }}"
state: directory
with_items: "{{ www_sites }}"
- name: Create public directory for each website
file:
path: "{{ www_root }}/{{ item.domain }}/public"
state: directory
with_items: "{{ www_sites }}"
- name: Create log directory for each website and give caddy write permissions
file:
path: "{{ www_root }}/{{ item.domain }}/logs"
state: directory
owner: caddy
group: caddy
mode: '0755'
with_items: "{{ www_sites }}"
Je ziet dat je dus ook in taken kunt verwijzen naar variabelen in Jinja-syntax: zo maken we een root-directory voor de websites aan met als pad {{ www_root }}, wat wordt vervangen door de waarde van de variabele www_root zoals je die ingesteld hebt voor deze server.
Webserver in vijf minuten
Als je deze Ansible-playbook nu uitvoert, heb je een webserver draaien, inclusief HTTPS via Let’s Encrypt. Uiteraard dien je er nog voor te zorgen dat het domein dat je in het configuratiebestand ingesteld hebt effectief naar deze server verwijst, en de inhoud van je website (als het om een statische website gaat) dien je ook nog in de juiste directory te plaatsen. Dat laatste kun je ook via Ansible doen, of via een cronjob of manueel via rsync afhankelijk van je manier van werken.
Valt je server ooit uit, dan hoef je alleen maar je Ansible-playbook opnieuw uit te voeren op een nieuwe server om je webserver weer in gang te hebben, en daarna de inhoud van je website weer op de juiste locatie te zetten. Zo ben je gemakkelijk op vijf minuten weer online. Zelf hebben we dit meegemaakt toen onze vps door een fout in de beheerinterface van onze serverprovider onvoorzien gewist werd. Omdat de hele serverconfiguratie in Ansible stond en de website een statische website met Nikola was, waren we zo na een kwartier (door de verplichte reset ontdekten we nog enkele foutjes in het Ansible-playbook) weer live.
En verder
We hebben maar een fractie besproken van de mogelijkheden van Ansible. Bekijk zeker de uitgebreide documentatie van het project. Grotere Ansible-playbooks ga je overigens eerder structureren in rollen, die je eenvoudig kunt delen met anderen op de website Ansible Galaxy. Zo hoef je niet meer het warm water opnieuw uit te vinden, maar kun je rollen van anderen in je playbooks gebruiken. Let wel op welke rollen je gebruikt, want de kwaliteit ervan varieert enorm. Verder worden de standaardmogelijkheden van Ansible uitgebreid door collections.
Je kunt Ansible ook uitbreiden met je eigen modules, die je in gelijk welke programmeertaal kunt schrijven, zolang die maar JSON-content teruggeven die de kern van Ansible kan inlezen. Ook je inventory kun je laten vullen door gelijk welk programma dat JSON teruggeeft. Die inventory kan dus veel complexer zijn dan een eenvoudig bestand.
Voor bedrijfsgebruik biedt Red Hat bovendien extra functionaliteit en ondersteuning, onder de naam Red Hat Ansible Automation Platform. Daarin zit onder andere Ansible Tower, een webgebaseerde console voor Ansible. De opensourceversie daarvan is AWX. Al met al heeft Ansible een lage instapdrempel, maar biedt het heel veel mogelijkheden voor configuratie van al je Linux-systemen.