Datamining en datascience worden steeds meer toegepast om ons heen. Big Data, social media-analyse, loggegevens van websites, locatiegegevens, Facebook, LinkedIn – de hoeveelheid gegevens groeit explosief! In deze introductie willen we je meenemen op de eerste stappen in het vakgebied van datamining, ook wel datascience geheten.
Open source-tools worden zeer breed ingezet in dit vakgebied. R heeft een vooraanstaande positie verworven, doordat de hoeveelheid bibliotheken angstaanjagend groot is en doordat de wetenschappelijke wereld nieuwe algoritmes en technieken zeer snel – zo niet meteen –implementeert. In R loop je nauwelijks achter bij de bleeding edge technologie. RStudio is de IDE naar keuze als je aan de slag wilt met R.
ANDERE TOOLS
Naast R en RStudio kun je ook kijken naar een meer GUI/canvasgedreven tool als KNIME. Voor social network-analyse is Gephi je tool. Voor textmining kun je met Python en NLTK aan de slag. Kortom, genoeg te doen als je stappen wilt zetten in de wereld van Big Data en datascience!
 1 De RStudio IDE
1 De RStudio IDE
INTRODUCTIE DATAMINING
Zoals je al aan de opsomming hierboven hebt kunnen zien, bestaat het vakgebied van datamining uit heel veel facetten. We hebben hier niet de ruimte noch is het onze bedoeling het hele vakgebied te beschrijven. Dit artikel heeft tot doel een eerste kennismaking te zijn met open source dataminingtools en meer specifiek R, met de R-Studio IDE. Om dit vorm te geven zullen we een specifieke dataminingtaak verder uitwerken en in een eenvoudige vorm doorwerken. Een veelvoorkomende dataminingtaak is het voorspellen van kansen op basis van gegevens die over mensen (klanten) zijn verzameld in een database, een zogenoemde classificatietaak.
DATASET
Wat hebt je nodig om te beginnen met datamining? Juist, data! Voor onze eerste dataminingoefening maken we de data zelf om alle controle te hebben over de datakwaliteit. Bij het registreren, verzamelen en vastleggen van gegevens gaat er natuurlijk altijd wat mis. Als je gaat dataminen, kom je missende/ontbrekende waardes tegen. Ook uitschieters (waardes die niet lijken te horen bij een kenmerk dat je meet, bijvoorbeeld de waarde 1000 als je leeftijd van personen in jaren meet, zijn aan de orde van de dag. Verder zijn er foutieve waarden, bijvoorbeeld symbolen waar je alleen getallen verwacht of andersom. Voor al die zaken moet je in de praktijk een oplossing zoeken. In de praktijk ben je tachtig procent van je tijd bezig met datavoorbereiding en twintig procent met het daadwerkelijk analyseren van dataminingresultaten. In ons voorbeeld maken we de gegevens zelf, zodat we deze problemen even voor ons uit kunnen schuiven…
BANNERSELECTIE
In ons voorbeeld ontwikkelen we een datamining-model dat de kans schat dat een klant een bepaald product koopt. Een dergelijk model kunnen we inzetten in een webshop door alleen die banners te tonen aan een specifieke klant met een hoge kans dat die het product koopt. In ons voorbeeld leggen we van de klanten in de webshop de leeftijd, het geslacht en het inkomen vast, bijvoorbeeld bij de registratie bij de webshop. Daarna meten we van een aantal klanten wat er gebeurt als we een banner laten zien van ons product. Als de klant het product koopt, registreren we de aankoop met een vlaggetje, bijvoorbeeld 1 als de klant koopt en 0 als de klant niet koopt. Het resultaat is een dataset met per regel een klant-record in de database. Op iedere regel staat een ID, leeftijd, geslacht, inkomen en het koopvlaggetje. De datamining- taak is nu om een relatie te vinden tussen de verzamelde klantgegevens (leeftijd, geslacht en inkomen) en het koopvlaggetje (1 of 0). Als we de classificatietaak goed kunnen uitvoeren met ons dataminingmodel op basis van de verzamelde gegevens, kunnen we het model toepassen op nieuwe klanten. Immers, zodra we weten wat de leeftijd, het geslacht en het inkomen van een nieuwe klant zijn, kunnen we met het dataminingmodel een kans uitrekenen dat deze klant interesse heeft in ons product! Als de kans groot is, laten we hem of haar een banner zien van ons product in de webshop, anders niet (of een andere banner waarvan de kans op aankoop groter is dan van ons product).
AAN DE SLAG
En nu de praktijk. Download R van R-project.org en download en open daarna RStudio desktop (zie afbeelding 1). Het scherm is verdeeld in drie delen, links de console en rechtsboven de workspace browser; hierin zie je welke data en variabelen er zijn geladen. Rechts onderin zie je een aantal tabs: Files, Plots, Packages en Help. Files, Plots en Help spreken voor zich; de packages verdienen uitleg. Dit zijn de bibliotheken waarmee je je statistische gereedschapskist in R naar wens kunt uitbreiden. Deze bibliotheken kun je downloaden via het zogenoemde Comprehensive R Archive Network (CRAN). Op dit moment zijn er 4513 pakketten beschikbaar! Om een indruk te krijgen van de mogelijkheden kun je nu in de console het volgende commando typen:
> demo()
Je krijgt nu een lijst met alle demo’s die beschikbaar zijn. In eerste instantie is de lijst beperkt, doordat alleen het base pakket is geladen. Een ander belangrijk commando is help(); van alle functies in R is een uitgebreide help beschikbaar, meestal met referenties naar wetenschappelijke publicaties met aan het einde een aantal voorbeelden hoe de functie kan worden gebruikt. Onmisbaar voor je eerste stappen in R, maar ook voor de ervaren gebruiker; omdat de mogelijkheden in R schier onuitputtelijk zijn, is het altijd handig als je met de helpfunctie snel een voorbeeld kunt opzoeken.
ONS PROJECT
In RStudio kun je losse scripts maken, maar ook werken met projecten. Maak je eerste project aan via Project, Create Project. Hier zie je direct dat je de mogelijkheid hebt om samen te werken met meerdere mensen door een project op Github te zetten of via SVN te delen. We kiezen de eerste optie, New Project, en geven het project een naam. Nu ben je klaar om je eerste R-script te maken. Je opent een leeg R-script via File, New, R script. Linksboven opent zich een leeg scriptbestand met de naam untitled.
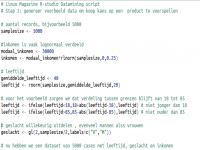 List 1 laat zien hoe je variabelen kunt genereren
List 1 laat zien hoe je variabelen kunt genereren
Stap 1: Dataset maken
In het voorbeeld hebben we uitgelegd dat we gegevens kunnen verzamelen in een webshop die als basis kunnen dienen voor het ontwikkelen van een voorspelmodel van de kans dat een specifiek product wordt gekocht. Omdat niet iedereen een webshop met echte gegevens voor handen heeft en omdat echte gegevens vaak vervuild zijn, ontbrekende waarden bevatten en ze eerst moeten worden opgeschoond alvorens we kunnen gaan dataminen, kiezen we er nu voor zelf een dataset te maken. Dat doen we als volgt (zie Listing 1): Kies het aantal records dat we willen genereren, bijvoorbeeld 5000. Voor ieder record kun je nu de klantkenmerken gaan maken die we in ons voorbeeld willen gebruiken (in ons voorbeeld leeftijd, geslacht en inkomen). Voor inkomen gaan we uit van een modaal inkomen van € 30.000,-. Vaak is inkomen lognormaal verdeeld. Om inkomensgegevens te genereren gebruiken we in R de functie rlnorm (zie help(rlnorm) voor wat meer achtergrond). De variabele inkomen bevat nu 5000 datapunten die lognormaal zijn verdeeld met een mediaan van 30.000. Om je een idee te geven hoe inkomen er nu uitziet, kun je bijvoorbeeld aan R een samenvatting vragen met summary(inkomen). Ook kun je eenvoudig een plaatje maken van de verdeling, een zogenoemd histogram, met hist(inkomen).
In Listing 1 zie je hoe je naast inkomen op dezelfde manier data genereert voor leeftijd en geslacht. Geslacht is geen numerieke waarde, maar een zogenoemde factor. Een factor wordt gebruikt in R om efficiënt categorievariabelen op te slaan. Probeer eens summary(geslacht) en help(factor) om te zien hoe de help in R ook kan worden gebruikt om concepten in R uit te leggen.
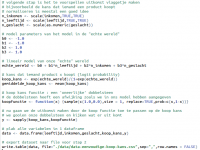
Listing 2 laat zien hoe je een verkoopvlaggetje kunt maken op basis van een kansmodel
KOOPVLAGGETJE
De volgende stap is het maken van een koopvlaggetje op basis van de gegevens die we al hebben aangemaakt voor leeftijd, inkomen en geslacht. We maken dus eigenlijk nu een model van de werkelijkheid dat we later, in stap 2, proberen terug te vinden met onze datamining-technieken! Laten we eens kijken hoe we dat kunnen doen; zie Listing 2. We schalen eerst onze klantkenmerken, zodat we in ons model de kenmerken goed met elkaar kunnen vergelijken. Immers, inkomen ligt in de orde van grootte van 10.000, terwijl leeftijd in de orde van grootte van 100 ligt. Dit is een factor 100 verschil! Daarna gaan we ons model, dat we in dit voorbeeld willen gebruiken, maken. Dit is als het ware de beschrijving van de ‘echte wereld’ in onze webshop. In ons voorbeeld gaan we uit van een eenvoudige, lineaire relatie tussen onze klantkenmerken en de verkoopkans. Ons model van de webshop-koopkans van ons product ziet er als volgt uit: model = -1 – leeftijd + inkomen + geslacht. Als we het model zouden willen beschrijven, kun je zeggen dat hoe ouder iemand is, hoe kleiner de kans dat iemand het product wil kopen. Daarnaast, als iemand een hoog inkomen heeft, neemt de kans toe dat hij of zij het product koopt. Voor geslacht hebben we een trucje uitgehaald; we hebben de categorie M/V geconverteerd naar 0/1 via de functie as.numeric(). Dus zeg maar, vrouwen kopen vaker dan mannen (wat natuurlijk altijd waar is, toch?). Ons model is nog geen kansmodel; hiervoor moet de waarde per definitie tussen 0 en 1 liggen. Om dit te doen gebruiken we de zogenoemde logit-functie (voor meer informatie zie de links aan het eind van dit artikel). De volgende stap is om op basis van ons kansmodel een simulatie te doen en voor iedere regel in de database vast te leggen of die klant wel of niet het product koopt. Dit kun je beschouwen als het gooien met een ‘oneerlijke’ dobbelsteen waarmee is geknoeid. Natuurlijk hebben wij er zelf mee geknoeid en weten we precies welke afwijking we hebben gemaakt, namelijk zoals we die in ons model hebben vastgelegd! Als laatste stap combineren we alle losse variabelen in één dataframe en schrijven we de dataframe weg naar een file, zodat we die in stap 2 als basis kunnen gebruiken. We hebben nu 5000 regels met data. Op iedere regel hebben we de klantkenmerken leeftijd, inkomen en geslacht met een koopvlaggetje (wel of niet) voor ons product. In stap 2 gaan we kijken of we met datamining kunnen voorspellen of iemand ons product wil kopen of niet!
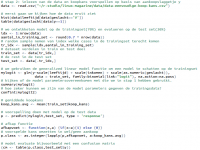
Listing 3: Het echte datamining-werk
CRISP DATAMINING CYCLUS
Veel datascientists maken gebruik van de Cross Industry Standard Process for Data Mining ofwel CRISP DM. Als je een dataset onder ogen krijgt, zul je eerst moeten begrijpen wat het probleem is dat je wilt onderzoeken (in ons voorbeeld willen we een banner tonen op de website van de shop). Daarna ga je naar de data kijken om te zien welke kenmerken er beschikbaar zijn, wat de kwaliteit is en hoe de relatie met de te voorspellen classificatievariabele is. In ons voorbeeld kunnen we datapreparatie buiten beschouwing laten, omdat we de gegevens in stap 1 zelf hebben gemaakt en precies klaar hebben gezet voor onze modeltaak. Dus we kunnen, als we begrijpen naar welke gegevens we kijken in relatie tot de voorspeltaak, een modeltechniek proberen en evalueren. Hier komt een belangrijk aspect van datamining en modelontwikkeling om de hoek kijken, namelijk evaluatie. Hoe bepaal je of een voorspelmodel enige waarde heeft? Hoe goed kun je voorspellen? Heb je een model nodig dat voor alle gevallen even goed moet kunnen voorspellen of zijn bepaalde typen fouten pijnlijker dan andere? Een goed voorbeeld hiervan is het voorspellen van een diagnose voor een ernstige ziekte. Je hebt in principe twee typen fouten in ons classificatievoorbeeld: cases waarvan je model aangeeft dat iemand een product koopt (of de ernstige ziekte heeft), maar in werkelijkheid blijkt dat de klant het product niet koopt (de patiënt de ziekte niet heeft). Dit zijn de zogenoemde false postives. En het andere type fout: het model geeft aan dat de klant het product niet koopt/de patiënt de ziekte niet heeft, maar in werkelijkheid blijkt dat de klant het product wel koopt/de patiënt de ziekte wel heeft. Dit zijn de zogenoemde false negatives. Je zult direct begrijpen dat afhankelijk van de onderliggende businesscase deze twee typen fouten in de meeste gevallen niet even belangrijk zijn. Een patiënt die ten onrechte wordt gediagnostiseerd met een ernstige ziekte, zal dat heel vervelend vinden. Maar de situatie dat een patiënt die naar huis wordt gestuurd met de geruststelling ‘dat er niets aan de hand’ is, terwijl hij/ zij een maand later met ernstige klachten alsnog wordt opgenomen, is echt onacceptabel. Er zijn enorm veel mogelijkheden om te evalueren. Het voert in dit eenvoudige voorbeeld te ver al deze mogelijkheden uit te werken; in ons voorbeeld gebruiken we een eenvoudige opdeling van alle beschikbare gegevens in een trainingset en een testset. We ontwikkelen het model op de trainingset en controleren of het model werkt op de testset aan de hand van een confusion matrix. Voor een echte praktijkcase is dit niet meer van deze tijd; we hebben zoveel rekenkracht tot onze beschikking dat er allerlei sampling- en bootstrapping- technieken beschikbaar zijn die de informatie in de gegevens veel efficiënter gebruiken om tot een eindresultaat te komen dan wat wij in ons voorbeeld doen. De laatste, niet onbelangrijke, stap is de toepassing van het datamining- resultaat. In ons voorbeeld zal er voor de keuze welke banner moet worden getoond, op iedere pagina van de webshop voor iedere ingelogde gebruiker een beslissing moeten worden genomen welke banner het meeste kans maakt. Je zult begrijpen dat dit volledig geautomatiseerd en in real-time moet worden ingeregeld, genoeg voer voor een artikel op zichzelf!

2 Crisp datamining-methode
Stap 2: Ontwikkelen van een datamining-model
De dataset in stap 1 is het uitgangspunt van ons dataminingvoorbeeld, maar de dataset zou net zo goed uit onze webserver kunnen worden getrokken. Als eerste gaan we kijken wat we in de dataset zien, zodat we begrijpen welke gegevens belangrijk zijn. Hiervoor zijn er heel veel mogelijkheden, bijvoorbeeld met het pakket ggplot2 of lattice. In Listing 3 vind je een aantal eenvoudige analyses die je zelf kunt uitbreiden naar de andere variabelen. Voor visuele analyse wil ik je ook zeker Mondrian niet onthouden. Dit open sourcepakket werkt samen met Rserve op de achtergrond. Nu zijn we toe aan de feitelijke datamininganalyse. Als eerste verdelen we de dataset in een deel om het model op te ontwikkelen, de trainingset, en een deel om het model op te evalueren, de testset. Daarna gaan we het feitelijke datamining-model trainen op de trainingset. De modeltechniek die we voor deze taak gebruiken, is een generalized linear model, toegespitst op een binominaal classificatieprobleem (zie help(glm) in de console). Met summary(mylogit) kunnen we bekijken wat het resultaat van het model is op de trainingsdataset. We zien een heleboel statistieken over het model. De kolom Estimate geeft de modelparameters (bèta’s uit stap 1) weer. De drie sterretjes op het einde geven aan of de parameter significant is (drie is zeer significant). Bijvoorbeeld de tweede bèta, voor leeftijd, wordt geschat op 1.06. In stap 1 hebben we deze parameter op 1.00 gesteld. We stellen dus vast dat we de parameters die we in stap 1 hebben gebruikt om met een ‘echte wereld’-model data te genereren, door het datamining-model haarfijn worden gereconstrueerd op basis van de trainingsdata alleen (dus zonder kennis over het ‘echte wereld’-model). De volgende vraag is of we dit model ook echt kunnen toepassen op gegevens die nog nooit zijn gezien door het model, de testdataset. Dit testen we door de predict()- functie toe te passen met het model en de testset als inputs. Het resultaat is een kans tussen 0 en 1. Deze kans moeten we nu vertalen naar een Ja of een Nee, wel of niet kopen. Hiervoor gebruiken we de afkapfunctie die de gemiddelde koopkans als afkapgrens neemt. Als we dit doen, kunnen we daarna een zogenoemde confusion matrix opstellen om te zien hoe goed de voorspelling overeenkomt met het echte gedrag van die klant. De confusion matrix op de testset ziet er, als het goed is, uit zoals in figuur 3. Van de 1500 cases zijn er 909 goed voorspeld; dat is zestig procent! Daarnaast hebben we 349 false positives – dit zijn cases waarvan ons model heeft voorspeld dat ze zouden kopen, maar die in werkelijkheid niet hebben gekocht – en 242 false negatives, waarbij het model heeft voorspeld dat deze mensen niet zouden kopen terwijl ze wel hebben gekocht.
CONCLUSIE
Open source is voor datamining-experts een zeer welkome aanvulling op de closed source-tools (van bijvoorbeeld SAS of IBM). Daarnaast hebben we in deze workshop laten zien dat R en RStudio zeer uitgebreide mogelijkheden hebben voor het analyseren van data. Het voorbeeld is natuurlijk maar een speelgoedvoorbeeld, maar geeft wel de essentie van de datamining-cyclus weer. Naast R en RStudio zijn er nog veel meer heel bruikbare open source-tools voor datascientists; misschien daarover later meer.
Hugo Koopmans is datascientist en managing partner bij DIKW Consulting. Hij houdt lezingen en geeft regelmatig trainingen op het gebied van datamining en advanced analytics. Je kunt hem bereiken via hugo.koopmans@dikw.com.
LINKS
RStudio www.rstudio.com
KNIME www.knime.org
Gephi https://gephi.org
NLTK http://nltk.org
Logit-functie http://en.wikipedia.org/wiki/Logit
Mondrian http://stats.math.uni-augsburg.de/mondrian