Een backup is pas écht veilig wanneer je nog een extra kopie bewaart op een andere locatie. Maak je thuis backups op een Raspberry Pi, dan kun je die bijvoorbeeld uploaden naar de cloud. In deze workshop bouwen we daarvoor een oplossing die met élk backupprogramma werkt. (door Filip Vervloesem. redacteur Linuxmagazine)
Thuis backups bewaren is in principe een prima optie, die veel voordelen biedt:
– het is goedkoop: je betaalt slechts éénmaal voor de aanschaf van een extra harde schijf om jaren backups te maken. Wil je nog meer zekerheid, koop dan meteen een tweede schijf en combineer beide schijven in een RAID-1 array. Gaat 1 van de 2 schijven stuk, dan is je backup nog steeds beschikbaar.
– het is snel: zowel het maken als herstellen van backups gaat érg snel.
– het stelt geen speciale eisen aan je internetverbinding, zoals een hoge uploadsnelheid of een onbeperkt maandelijks datavolume.
Waarom de cloud?
Toch is er één groot nadeel: een backup op dezelfde locatie biedt géén bescherming tegen een aantal rampzalige situaties. Denk bijvoorbeeld aan diefstal, brand of waterschade. Toegegeven, de kans is klein dat je in zo’n situatie terechtkomt, maar onmogelijk is het niet. Wil je absolute zekerheid dat je backup altijd beschikbaar blijft, dan moet je een tweede kopie bewaren op een andere locatie. Gelukkig is dat tegenwoordig erg eenvoudig, dankzij snelle internetverbindingen en goedkope opslag in de cloud. Omdat we ons niet willen vastpinnen op één specifiek backupprogramma, kiezen we ervoor om de kopie naar de cloud los te koppelen van de eigenlijke backup. Daarvoor synchroniseren we gewoon de backupmap na het het maken van een lokale backup. Iedereen kan deze workshop dus volgen, ongeacht de gebruikte backupsoftware.
Om een backup in de cloud te bewaren, heb je natuurlijk opslagruimte nodig. Weersta aan de verleiding om gratis opslagruimte te kiezen, want die biedt nooit dezelfde garanties als een dienst waarvoor je betaalt. Wij kozen voor Amazon als provider: een grote speler met een bewezen betrouwbaarheid én verschillende mogelijkheden om de kosten voor je backups zo laag mogelijk te houden. De cloud storage vind je terug onder de naam S3, een onderdeel van de Amazon Web Service of kortweg AWS. Heb je nog geen AWS-account, maak die dan eerst aan https://aws.amazon.com/s3. Kies je voor een Basic Plan, dan is de account op zich gratis en betaal je enkel voor de gebruikte opslagruimte. Je moet wel een creditcard koppelen aan je account om de maandelijkse facturen te betalen. Het eerste jaar krijg je trouwens 5GB gratis opslagruimte. Dat is voldoende om deze workshop te volgen en zo een idee te krijgen of het wat voor jou is of niet. Zodra je account geactiveerd is, log je met je e-mailadres in als Root user op de AWS Management Console: https://console.aws.amazon.com of ga naar AWS Partner Page – TEQnation
## 01_aws.png: Gebruik het e-mailadres van je AWS-account om als Root user in te loggen.
S3
Vooraleer we effectief aan de slag gaan met S3, moeten we eerst nog wat details bespreken. S3 storage is zeer betrouwbaar, omdat jouw data verspreid staat over meerdere datacenters. Amazon garandeert dat jouw data zelfs beschikbaar blijft indien twee datacenters tegelijkertijd uitvallen. Qua locatie geeft Amazon de keuze om jouw data te bewaren in verschillende locaties in Europa (zoals Frankfurt en Parijs), mocht je liever geen data in de VS willen plaatsen. Om de maandelijkse kostprijs in te schatten voor jouw backups, is wel wat rekenwerk vereist. Amazon S3 kent immers geen eenvoudige maandelijkse prijs per gigabyte, omdat die verschilt naargelang de gekozen opties en jouw gebruikersprofiel. Binnen S3 biedt Amazon immers verschillende storage classes aan, die elk geschikt zijn voor specifieke toepassingen. Voor elke storage class gelden er aparte tarieven voor de eigenlijke opslag, het opvragen van data en de gebruikte bandbreedte. Het volledige overzicht vind je op https://aws.amazon.com/s3/pricing.
Kostprijs
Stel dat je 500GB aan backups hebt. Bewaar je die met de S3 Standard storage class in Frankfurt, dan betaal je maandelijks $0.0245 per GB voor de opslag = $12.25. Daarnaast is er ook een kost van $0.0054 per 1000 upload requests. Bevat jouw backup bijvoorbeeld 100.000 bestanden, dan betaal je éénmalig $0.54 om die te uploaden (voor download requests is er ook een kost, maar die is nog een factor 10 lager). Tot slot betaal je nog voor de gebruikte bandbreedte. Dataverkeer naar Amazon S3 (=backup maken) is altijd gratis. Voor dataverkeer van Amazon S3 naar jouw computer (=backup herstellen) betaal je $0.09 per GB. Het herstellen van een backup van 500GB kost dus $45. Dat lijkt misschien duur, maar anderzijds is de kans erg klein dat je ooit effectief al jouw data zult moeten herstellen. De backups bij Amazon gebruik je immers enkel wanneer jouw lokale backup verloren is gegaan.
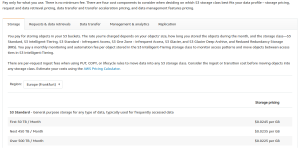
## 02_pricing.png: De kostprijs van S3 bestaat uit verschillende componenten.
Storage classes
Voor een backup van 500GB betaal je dus zo’n $150 per jaar met S3 Standard. Dat lijkt nogal duur, maar het kan gelukkig ook goedkoper! Voor data die je zelden downloadt, kies je beter S3 Standard – Infrequent Access. Het prijskaartje ziet er dan als volgt uit:
– $0.0135 per GB voor de opslag = $6.75 per maand
– $0.01/$0.001 per 1000 upload/download requests. Dit is nog altijd maar $1 om éénmalig 100.000 bestanden te uploaden
– $0.10 per GB die je downloadt
De backup kost nu nog een kleine $80 per jaar, en de kostprijs voor het volledig herstellen is maar $5 duurder ($50 in plaats van $45). Voor opslag op lange termijn zijn er tot slot nog de S3 Glacier en S3 Glacier Deep Archive storage classes. In dat geval kost onze backup:
– $0.0045 (Glacier) of $0.0018 (Glacier Deep Archive) per GB voor de opslag = $2.25 of $0.9 per maand
– $0.06 per 1000 uploads, ofwel $6 voor 100.000 bestanden
– $0.09 à $0.12 (Glacier) of $0.9 à $0.11 (Glacier Deep Archive) per GB die je downloadt, plus een kost per 1000 bestanden (zie verder).
De totaalprijs per jaar komt zo uit op een goede $30 voor Glacier en slechts $12 voor Glacier Deep Archive.
Herstellen
De Glacier storage classes bieden erg goedkope opslagruimte, maar de kostprijs voor het herstellen van je backup loopt al gauw op. De precieze prijs hangt af van hoe snel je jouw data nodig hebt en hoeveel bestanden jouw backup bevat. Kan je tot 12 uur wachten, dan betaal je iets minder dan $50 voor de volledige backup, plus $0.03 per 1000 bestanden. Wil je binnen de 5 uur jouw data? Dat kost dan $50 à $60, plus $0.06 (Glacier) of $0.12 (Glacier Deep Storage) per 1000 bestanden. Nog sneller herstellen is enkel mogelijk met de Glacier storage class, maar daarvoor moet je diep in je buidel tasten. Je betaalt dan maar liefst $12 extra per 1000 bestanden die je downloadt! Een backup met 500GB aan data en 25.000 bestanden kost dus bijvoorbeeld $360 om te herstellen. Voor dat geld kun je de data ook 12 jaar bewaren in de Glacier storage class. Lees zeker alle details na over de Infrequent Access en Glacier storage classes alvorens je beslist om die te gebruiken. Beide classes gaan immers uit van een minimale bestandsgrootte én een minimale levensduur van de data. Bevat jouw backup veel kleine bestanden of bestanden die snel weer verwijderd worden, dan kan het kostenplaatje er helemaal anders uitzien.
Object storage
Om te starten met S3, klik je in de Management Console op “All services” > “Storage” > “S3” . In feite is S3 geen bestandssysteem met mappen en bestanden, maar het is een vorm van object storage. De precieze technische details hoef je niet te kennen. Onthoud vooral dat je binnen S3 spreekt van objecten in plaats van bestanden en dat je in plaats van een top level directory een zogenaamde bucket nodig hebt. Klik dus op “Create bucket” om je eerste bucket aan te maken. Kies een naam en een locatie om je data te bewaren en controleer of de optie “Block all public access” is aangevinkt. De overige opties hoef je niet aan te passen. Merk trouwens op dat de naam van de bucket uniek moet zijn binnen Amazon AWS (en dus niet enkel binnen jouw account)! Een eenvoudige naam zoals “backup” kun je dus niet meer nemen.
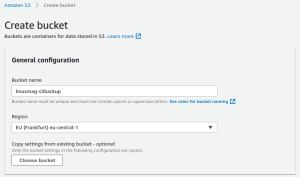
## 03_bucket: Data bewaar je in buckets in S3.
Toegangsrechten
In principe kun je de AWS Root user gebruiken om je backups te uploaden, maar erg veilig is dat niet. Je maakt beter een aparte gebruiker aan met beperkte toegangsrechten tot de benodigde bucket. Daarvoor moet je even een ommetje maken langs een andere service, namelijk IAM (via “Services” > “Security, Identity & Compliance”). Klik in de linkerbalk op “Policies” en vervolgens op “Create policy”. Je kunt de benodigde toegangsrechten in de Visual editor instellen, of je kunt de code uit listing 1 in het JSON-tabblad invoeren. Vergeet niet om de correcte bucket-naam voor jouw account in te vullen! Je kunt de uit listing 1 ook downloaden via https://linuxmag.nl/category/listings. Onze policy laat volgende acties toe:
– een lijst van beschikbare buckets opvragen (ListAllMyBuckets)
– meer informatie opvragen over de bucket “linuxmag-s3backup” (ListBucket, GetBucketLocation en GetBucketPolicy)
– objecten uploaden (PutObject), downloaden (GetObject) of verwijderen (DeleteObject) in die bucket
########## begin listing 1 ##########
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetBucketPolicy"
],
"Resource": "arn:aws:s3:::linuxmag-s3backup"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::linuxmag-s3backup/*"
}
]
}
########## einde listing 1 ##########
Klik vervolgens op “Users” > “Add user” om een gebruiker aan te maken. Kies een naam (bijvoorbeeld “s3backup”) en vink de optie “Programmatic access” aan. In de volgende stap kies je “Attach existing policies directly” en selecteer je de policy die je zonet aangemaakt hebt. Tags hoef je niet in te stellen. Klik tot slot op “Create user” en kopieer de “Access key ID” en “Secret access key”, want die heb je meteen nodig om te bucket te gebruiken.
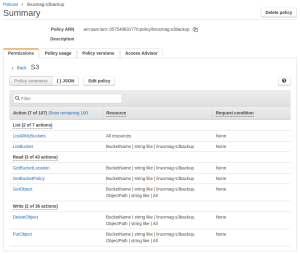 ## 04_policy.png: De policy bepaalt welke toegang de gebruiker krijgt tot jouw S3-opslagruimte.
## 04_policy.png: De policy bepaalt welke toegang de gebruiker krijgt tot jouw S3-opslagruimte.
Commandline
Om onze backup te synchroniseren met Amazon S3, gebruiken we de aws commandline tool op een Raspberry Pi. Je kunt de laatste versie downloaden vanaf de website van Amazon (zie Commandline tips verder in dit nummer), maar voor het gemak installeren we hier gewoon de versie die bij het Raspberry Pi OS zit:
$ sudo apt install awscli
Daarna configureer je aws met volgend commando:
$ aws configure
Vul daarbij de credentials in van de gebruiker die je had aangemaakt. De overige instellingen hoef je niet aan te passen. De “Default Region” is bijvoorbeeld niet van belang, omdat je jouw bucket al hebt aangemaakt in de correcte locatie.
Een eerste test
Aws is nu helemaal klaar om te communiceren met Amazon S3. Probeer eerst eens om één bestand te uploaden:
$ aws cp access.log s3://linuxmag-s3backup/
Nadien kijk je even in de Management Console of het bestand in de bucket verschenen is. De te gebruiken storage class stel je trouwens niet in op het niveau van de bucket, maar op object-niveau. Je kiest die dus tijdens het uploaden van een object, al kun je het ook nadien aanpassen. Standaard gebruikt aws de storage class “Standard”, wat niet de beste keuze is voor backups. Wil je bijvoorbeeld overstappen op Infrequent Access, voeg dan volgende optie toe aan het aws-commando:
--storage-class STANDARD_IA
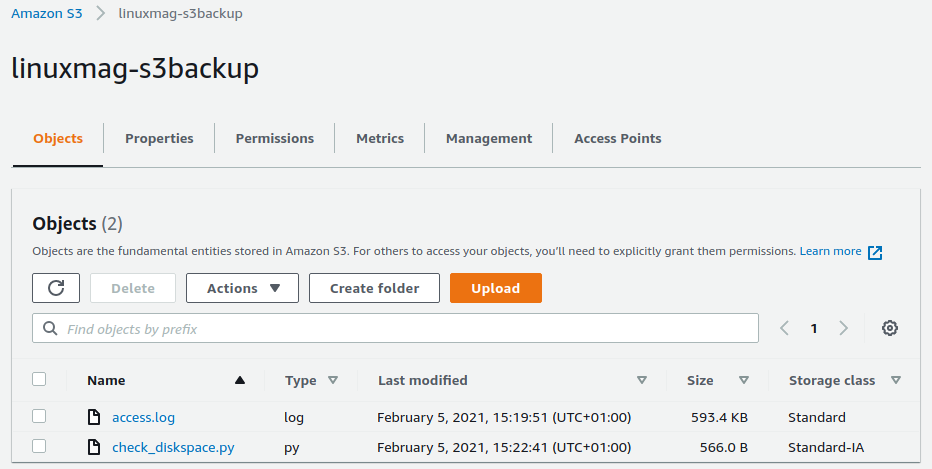
De twee overige storage classes zijn GLACIER en DEEP_ARCHIVE. Upload je een nieuw object, dan krijgt het meteen de nieuwe storage class (zie het object check_diskspace.py in afbeelding 5).
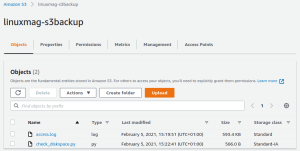
## 05_test.png: De te gebruiken storage class stel je in tijdens het uploaden van een object.
Synchroniseren
Nu staat alles klaar om jouw backup effectief te synchroniseren naar Amazon S3. Dat is erg eenvoudig met het sync-subcommando van aws s3. Vergeet niet om de optie –delete toe te voegen om verwijderde bestanden van de bronmap ook in de doelmap te verwijderen:
$ aws s3 sync /home/pi/backup/ s3://linuxmag-s3backup/Pi/ --delete
In bovenstaand voorbeeld kopiëren we de backups in /home/pi/backup naar een submap ‘Pi’ in onze bucket. Zo houd je backups van verschillende systemen netjes van elkaar gescheiden. Je kunt natuurlijk ook een afzonderlijke bucket aanmaken voor elk systeem, maar dat is eigenlijk enkel nodig als je verschillende toegangsrechten wilt instellen voor elk systeem.
## 06_sync.png: Met aws sync synchroniseer je de lokale backupmap met de S3 opslagruimte in de cloud.
Inplannen
De laatste stap is om jouw cloud backup op regelmatige basis in te plannen. Hoe je dat best doet, hangt af van jouw huidige backupprocedure. Maak je manueel backups, vergeet dan niet om het aws-commando op de Pi te starten na elke backup. Dat doe je best binnen een screen-sessie, zodat de backup netjes blijft draaien wanneer je de ssh-verbinding naar je Pi afsluit en je laptop of desktop uitschakelt. Installeer het screen-pakket, start vervolgens:
$ screen bash
En voer het aws-commando uit binnen die shell. Ontkoppel de screen-sessie daarna met Ctrl-a-d en log uit van de Pi. Nadien kun je de screen-sessie weer oproepen met:
$ screen -dr
Heb je je backups volledig geautomatiseerd? Dan wil je het aws-commando allicht ook automatisch laten uitvoeren, via cron. Dat vergt wel iets meer werk, want je wilt zeker op de hoogte gebracht worden in geval van problemen. Je schrijft dus best een klein script dat controleert of het aws-commando succesvol uitgevoerd was en jou via e-mail verwittigt als dat niet het geval was.