Ruim een decennium geleden veranderde virtualisatie de manier waarop in datacentra gewerkt werd. Inmiddels draaien er meer servers virtueel dan fysiek en lijkt de tijd rijp voor de volgende stap. Als je de belanghebbenden moet geloven, wordt het tijd om allemaal over te gaan naar de cloud. Wil je meer praktische hands on informatie over cloud en virtualisatie kom dan naar de eerste editie van de Open Tech Day , 20 April as in de Jaarbeurs te Utrecht.
Laten we om te beginnen eerst wat duidelijkheid scheppen. Dé cloud bestaat namelijk niet. Er zijn heel veel verschillende verschijningsvormen van cloud computing. Waar we het in dit artikel over hebben, is ‘Infrastructure as as Service (IaaS)’. Dat is – zoals ze het in het Engels zeggen – “Virtualization on steroids”. In een IaaS cloud wordt een platform geboden waarop klanten eenvoudig virtuele machines kunnen uitrollen, zonder zich zorgen te maken over installatie, locatie, networking en al die andere lastige zaken waar doorgaans netwerkbeheerders voor nodig zijn.
IaaS cloud op zich is niet nieuw. Zo ongeveer een decennium geleden begonnen de eerste initiatieven, vaak gedreven door verschillende vendors. Ook was er binnen de Linux wereld Eucalyptus, het platform voor elastic computing, waar Ubuntu al heel vroeg een significante rol in speelde. Hoewel het erop leek dat Eucalyptus heel groot zou worden, is dat niet echt gebeurd. Ondertussen waren veel andere partijen ook met hun eigen IaaS oplossingen gekomen. Denk aan Microsoft met Azure of VMware met vSphere Director. Daarnaast hadden NASA en RackSpace services ontwikkeld die samen heel handig gebruikt konden worden als implementatie van cloud computing.
De basis van OpenStack
Waarschijnlijk was het niet eens zozeer de kwaliteit van de services die door NASA en RackSpace geboden werden die ervoor zorgden dat OpenStack zich kon ontwikkelen tot de nieuwe standaard op het gebied van cloud computing. Veel belangrijker was het gegeven dat dit nieuwe initiatief als een open standaard gepresenteerd werd, dat bestond uit open source projecten die nauwkeurig op elkaar afgestemd werden. Dat had al snel een grote aantrekkingskracht op heel veel bedrijven, die allemaal op hun eigen wijze bij wilden dragen aan de ontwikkeling van dit nieuwe platform.
Waar verschillende commerciële bedrijven samen gaan werken om een oplossing te maken, bestaat natuurlijk het risico dat één bedrijf de ontwikkelingen naar zich toe trekt. In de OpenStack community wordt dat probleem tegengehouden door het OpenStack consortium, een genootschap dat de standaarden definieert waar anderen zich aan dienen te houden om officieel onderdeel te worden van OpenStack.
De besluitvorming over OpenStack gaat verder dan alleen maar een aantal lieden die vanuit de gedachte van open source bepalen wat wel en niet in OpenStack terecht zal komen. Een belangrijke rol wordt gespeeld door de OpenStack gebruikersconferentie die twee keer per jaar plaatsvindt en waarop de nieuwste release van OpenStack gelanceerd wordt.
Tot nu toe hebben in het vijfjarige bestaan van OpenStack de vernieuwingen zich heel snel opgevolgd. Zó snel dat het bijna een dagtaak was om alle ontwikkelingen bij te houden. Sinds de release van november 2014 (de Juno release), lijken de ontwikkelingen in een iets langzamer vaarwater terecht te zijn gekomen. De kerncomponenten zijn nu zo ongeveer wel uitgestabiliseerd en rijp om in productie genomen te worden.
Linux en OpenStack
Wat OpenStack voor Linux beheerders vooral interessant maakt, is dat het een platform is dat voor een heel groot deel op Linux draait. Alle servers die een rol spelen in het beheer van de infrastructuur zijn sowieso Linux (zelfs als die servers worden aangeboden in een proprietary variant, zoals het geval is bij bijvoorbeeld het VMware Integrated OpenStack platform waarop gewoon Ubuntu gebruikt wordt om die services aan te bieden). Daarnaast is OpenStack, net als Linux, een soort samengeraapt zootje van diverse onderdelen waarbij de verschillende aanbieders elk de mogelijkheid hebben hun eigen accenten te leggen.
Als je aan het werk wilt met OpenStack, zal je doorgaans een OpenStack platform uit moeten kiezen. Het begint met een fundamentele keuze: wil je een doe-het-zelf cloud of kies je liever voor een platform waarin heel veel ingewikkelde zaken op voorhand geregeld zijn?
De meest uitdagende manier om een OpenStack cloud te bouwen, is op basis van een doe-het-zelf cloud. Hierbij bepaal je op welk Linux platform je de cloud wilt bouwen en daar bovenop configureer je de rest zelf. Er zijn drie gangbare platforms voor OpenStack: (1) Ubuntu, (2) Red Hat en aanverwanten zoals CentOS en Fedora, en (3) SUSE.
Als je bepaald hebt welk onderliggend platform je wilt gebruiken, bestaat de volgende stap eruit de installatiehandleiding te downloaden van openstack.org en aan het werk te gaan. Deze installatiehandleiding bestaat uit heel veel lange commando’s die je in de juiste volgorde één voor één uit moet voeren om de verschillende onderdelen te configureren. Dit is sowieso alleen maar te doen als je heel goed thuis bent in Linux networking, storage, high availability en virtualisatie en zelfs dan ben je vaak wel een week of twee zoet voordat er een basis cloud-infrastructuur staat.
OpenStack distributies
Omdat de handmatige configuratie op zijn zachts gezegd uitdagend is, zijn er een aantal cloud distributies op de markt. Ook deze worden aangeboden door de grote spelers op het gebied van Linux, zoals Ubuntu, Red Hat en SUSE, maar daarnaast zijn er ook andere partijen die een OpenStack cloud distributie hebben. Zo heeft HP er een, wordt de Mirantis OpenStack distributie regelmatig gebruikt en heeft ook virtualisatie-gigant VMware de arena betreden en biedt sinds een paar maanden VMware Integrated OpenStack.
Voor de eindgebruiker is een kant en klare cloud distributie aan te raden, omdat de installatie er aanzienlijk eenvoudiger door wordt. Als Linux-techneut kan je het eigenlijk niet maken, omdat de cloud distributie heel veel aan het zicht onttrekt en dingen gemakkelijk maakt die daardoor heel lastig te troubleshooten zijn als er iets mis gaat. Zie het maar alsof elke cloud distributie zijn eigen YaST maakt (verwijzend naar het beheerplatform dat gangbaar is op SUSE omgevingen), waarbij taken eenvoudig gemaakt worden, maar de achterliggende techniek voor een groot deel aan het zicht onttrokken wordt. Een cloud distributie is wel een gemakkelijk opstapje om snel een werkende cloud te installeren om een mooi startpunt te creëren van waaruit je verder kunt werken.
De componenten
Nu je enig idee hebt hoe OpenStack als oplossing in elkaar zit, bekijken we de verschillende onderdelen. Zonder de bedoeling te hebben volledig te zijn, zien we de volgende onderdelen in elke OpenStack cloud:
* Nova: virtualisatie en beheer;
* Glance: opslag van kant en klaar te gebruiken images;
* Cinder: opslag in blokken;
* Swift: object gebaseerde opslag;
* Neutron: cloud networking;
* Horizon: een web gebaseerd beheersplatform;
* Keystone: toegangsbeheer.
Om de onderdelen goed te kunnen plaatsen, moeten we eerst een beeld vormen hoe in een OpenStack omgeving gevirtualiseerd wordt. Als een eindgebruiker een virtuele machine wil gebruiken, dan moet die virtuele machine natuurlijk ergens draaien. Nova is de service die ervoor zorgt dat een hypervisor platform beschikbaar gesteld wordt voor dit doel.
Kenmerkend aan een OpenStack omgeving, is dat gebruikers van de cloud meerdere virtuele machines kunnen uitrollen en dat die overal moeten kunnen draaien. Het maakt niet uit of vijf verschillende virtuele machines van dezelfde klant in vijf fysiek gescheiden datacentra voorkomen, vanuit de beleving van de klant moet het eruit zien alsof ze in hetzelfde LAN voorkomen. Om die reden is er cloud networking nodig, waarin networking zelf wordt losgekoppeld van de onderliggende fysieke infrastructuur. Dat klinkt moeilijk en dat is ook moeilijk. In de meeste cursussen die ik over dit onderwerp geef, is een dag nodig om cloud networking goed te kunnen plaatsen.
Initieel werd cloud networking ook geboden door de Nova service, maar omdat het zo’n complex domein is, is er een aparte service voor in het leven geroepen met de naam Neutron.
Het volgende aspect van het gebruik van cloud is dat de virtuele machines snel beschikbaar gemaakt moeten worden. Dat betekent dat je de service niet zou moeten installeren, maar dat ze uitgerold worden op basis van bestaande images. Deze images worden beheerd door de Glance Image services.
In Glance worden verschillende images aangeboden van besturingssystemen. Soms gaat het om geminimaliseerde versies van bestaande besturingssystemen, soms gaat het om hele nieuwe distributies. Het image wordt vervolgens gekoppeld aan een template dat bepaalt hoeveel RAM en CPU cores er beschikbaar zijn. Op basis daarvan kan je gewoon een image aanklikken om aan het werk te gaan. Het idee is dat je als eindgebruiker zo eenvoudig even een virtuele machine kunt huren en als je klaar bent met die virtuele machine wordt hij net zo eenvoudig weer afgesloten.
Dat je zo als eindgebruiker even tijdelijk een virtuele machine uitrolt, brengt wel een extra uitdaging met zich mee. Er is namelijk geen oplossing voor opslag. Als gebruiker wordt je geacht om alles wat je wilt bewaren buiten de virtuele machine op te slaan. De beschikbare opslag is – zoals het genoemd wordt – “ephemeral”, vergankelijk dus. Dat is een mooie manier om te zeggen dat alles weg is als je de virtuele machine uitzet.
Nu zijn er natuurlijk situaties denkbaar waarin de gebruiker gehecht is aan de gegevens die hij heeft aangemaakt. Om die reden is er Cinder, wat voorziet in block storage. Cinder zorgt ervoor dat volumes aangeboden kunnen worden die aan een virtuele machine (in OpenStack terminologie wordt dat overigens een Instance genoemd) gekoppeld worden en waarop gegevens permanent opgeslagen worden.
Flexibele opslag
Nu is het begrijpelijk dat cloud gebruikers gegevens op willen slaan, maar het introduceert ook een nieuw probleem. Een IaaS cloud moet zó flexibel zijn dat een instance overal ter wereld moet kunnen draaien. Als je dan vervolgens block storage nodig hebt waar uiteindelijk de gegevens toch op fysieke schijven op gaat slaan, werkt dat behoorlijk beperkend. Om die reden wordt gebruik gemaakt van object based storage, dat aangeboden wordt door de al wat oudere service Swift, of door het veel nieuwere Ceph.
In object based storage heb je niet langer te maken met oude vertrouwde bestanden, maar wordt gebruik gemaakt van binaire objecten. Dat kan je vrij eenvoudig zien: je oude vertrouwde bestand wordt niet langer in blokken opgeslagen in een bestandssysteem, waarin het dan door middel van een bestandsnaam teruggevonden kan worden, maar als brokjes binaire data die op verschillende servers overal op de wereld neergezet kunnen worden. Die binaire brokjes data worden gerepliceerd opgeslagen en verspreid over meerdere locaties neergezet.
Als je dan vanuit je applicatie een bestand gaat openen, worden al die binaire brokjes heel snel bij elkaar geraapt, zonder dat het echt uitmaakt waar je het vandaan haalt. Het idee hierachter is dat het echt niet meer uitmaakt of je zo’n brokje uit Groningen of Galveston haalt, omdat er gelijktijdig heel veel acties gestart worden om de benodigde gegevens binnen te halen. Dit gaat net zo snel als het inlezen van een bestand van je oude bekende harde schijf. Het enige vereiste is bandbreedte, heel veel bandbreedte, want die binaire brokjes moeten wel gesynchroniseerd worden nadat ze gerepliceerd zijn opgeslagen.
RESTful API
Bij het werken met object based storage heb je niet langer te maken met de oude manier van toegang tot bestanden, maar met toegang die gebaseerd is op RESTful API. RESTful API is het protocol dat door alle onderdelen in OpenStack gebruikt wordt. Dit protocol lijkt heel veel op het HTTP protocol (en is ook in grote mate op die standaard geïnspireerd). De introductie van de RESTful API om bestanden binnen te halen is echter totaal anders dan de oude bekende manier van toegang tot bestanden en daarom kan de bestandstoegang niet zomaar zonder meer plaatsvinden.
De oplossing hiervoor is echter niet bijzonder ingewikkeld. Een instance in OpenStack werkt gewoon met volumes die opgeslagen worden in Cinder of met images die beschikbaar gesteld worden door Ceph. En op de achtergrond maken Cinder en Ceph gebruik van object based storage dat ervoor zorgt dat dat allemaal heel erg transparant en eenvoudig geregeld wordt. Afbeelding 1 geeft een schematisch overzicht van hoe dat allemaal werkt.
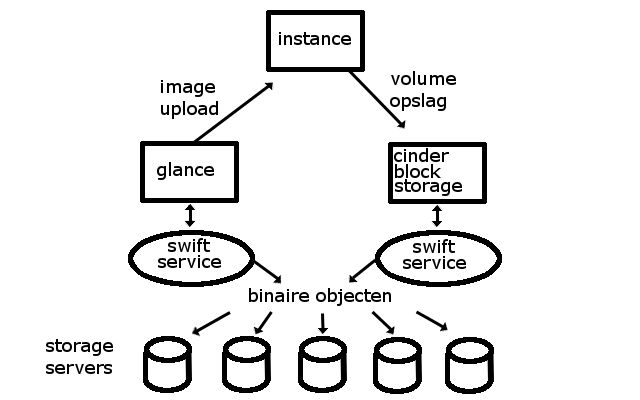
Schematisch overzicht van object based storage
Tot zover hebben we bijna alle belangrijke componenten besproken van een OpenStack cloud omgeving. Het enige dat nog ontbreekt, is een platform waarin je het allemaal eenvoudig kunt regelen. De vele ingewikkelde en lange commando’s zijn niet echt gebruikersvriendelijk. De OpenStack cloud is immers gemaakt voor de eindgebruikers die op basis van een paar klikjes een instance kunnen deployen. Voor dat doel is Horizon Dashboard gemaakt: een browser-gebaseerde user interface waarin instances redelijk eenvoudig uit te rollen zijn – zie afbeelding 2.
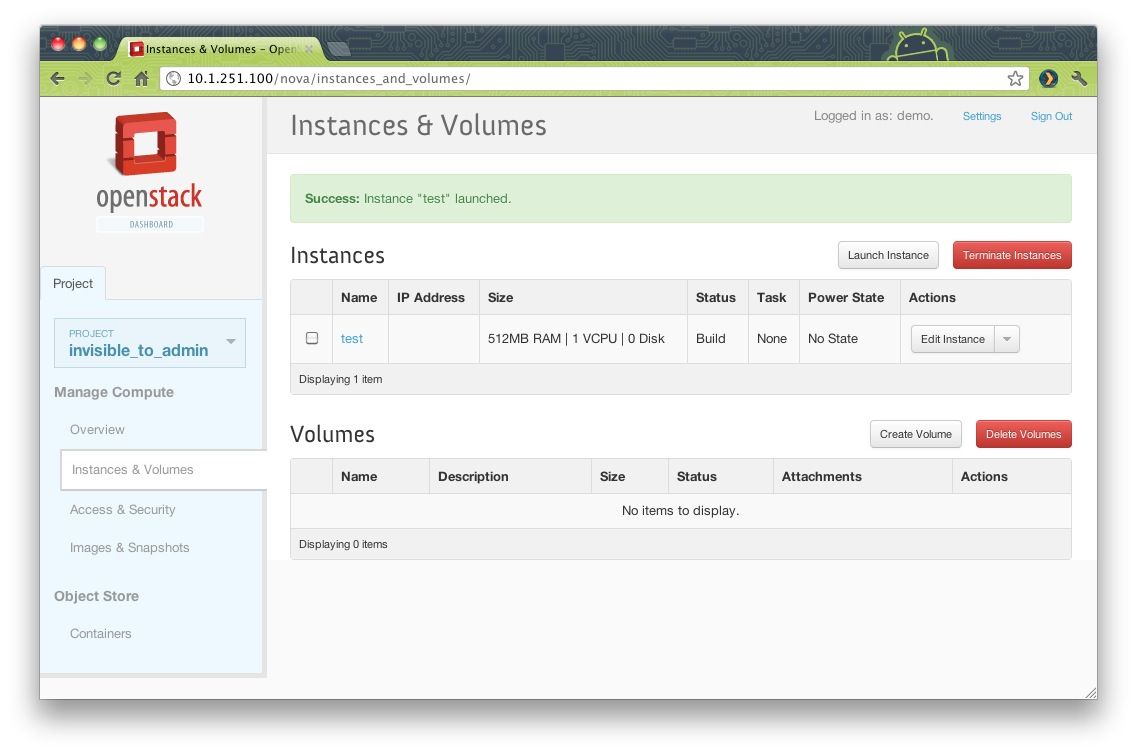
Eenvoudig beheer vanuit de Horizon Dashboard interface
Toegangsbeheer
Op basis van de informatie tot nu toe, heb je waarschijnlijk begrepen dat OpenStack behoorlijk complex in elkaar zit. Verschillende onderdelen moeten beschikbaar gesteld worden aan verschillende gebruikers van de cloud (de tenants), waarbij het ook nog gemakkelijk en veilig moet zijn om de omgeving van de ene tenant totaal onzichtbaar te maken voor die van de andere tenant. Hiervoor is een goed systeem voor toegangsbeheer nodig: Keystone.
In Keystone worden alle componenten van OpenStack gedefinieerd. Dat moet natuurlijk schaalbaar gebeuren en daarom worden de Keystone gegevens opgeslagen in een database die fysiek wordt aangeboden door een enkele relationele database (zoals MariaDB) of een hele farm van relationele databases die met elkaar samenwerken.
In die database worden de tenants gedefinieerd en de verschillende services die voorkomen in de projecten (de omgevingen) die door die tenants gebruikt worden. Het systeem dat daarvoor gebruikt wordt, is in te vergelijken met Kerberos, waarbij gebruik gemaakt wordt van authentication tokens die tijdelijk beschikbaar gesteld worden aan de verschillende gebruikers en servers die het nodig hebben.
Hypervisor support
Misschien is het je opgevallen dat we het gehad hebben over de instances, wat feitelijk virtuele machines zijn, zonder het onderliggende platform te noemen waarop die instances moeten draaien. Het leuke is dat dit in een OpenStack-omgeving niet echt uitmaakt. Welke hypervisor je ook gebruikt, het is voor de Nova service die zorgdraagt voor het uitrollen van virtuele machines in wezen maar een bijzaak. De Nova service praat door middel van een agent met een specifiek merk hypervisor. Vaak is dat een KVM hypervisor, maar het kan ook VMware vSphere (of direct op ESX) zijn en zelfs Microsoft Hyper-V behoort tot de mogelijkheden. Daarnaast is het mogelijk om verschillende hypervisor platforms te integreren in één OpenStack oplossing. Live Migration van virtuele machines tussen die verschillende hypervisor platforms is nog niet echt mogelijk, maar het geeft wel aan dat OpenStack niet voor niets OpenStack heet. Het gaat immers met recht om een stack van oplossingen die openstaan voor alles wat je je maar voor kunt stellen.
En verder
In dit artikel heb je gelezen wat OpenStack is en uit welke onderdelen het bestaat. Is je interesse nu gewekt? Ga dan als volgende stap eens aan de slag met OpenStack op basis van bijvoorbeeld de documentatie op OpenStack.org of gebruik een cloud distributie van één van de distributeurs. Persoonlijk ben ik nogal gecharmeerd van het platform dat Red Hat aanbiedt via rdo.redhat.com, maar soortgelijke oplossingen vind je ook bij SUSE of bij Ubuntu.